监控告警
在生产过程中,服务的稳定是非常重要的,而保证服务的稳定,一个是需要保证代码质量的稳定,一个是需要有完善的服务监控和告警,这里带大家搭建一套联犀监控告警体系.联犀在调研了数款监控平台之后,选用了夜莺来作为联犀官方支持的监控告警平台,当然,大家也可以只只使用Prometheus来进行监控,都是Prometheus生态的,这里带大家搭建起夜莺的监控体系.
安装
联犀直接通过docker的方式集成进来,大家只需要docker运行即可使用.
我们先进入到 things/deploy/docker/run-all
- 打开联犀服务链路追踪和Prometheus上报:
- 启动监控服务:
docker compose -f docker-compose-monitor.yml up -d - 打开夜莺:
http://localhost:17000默认账号:root 密码: root.2020
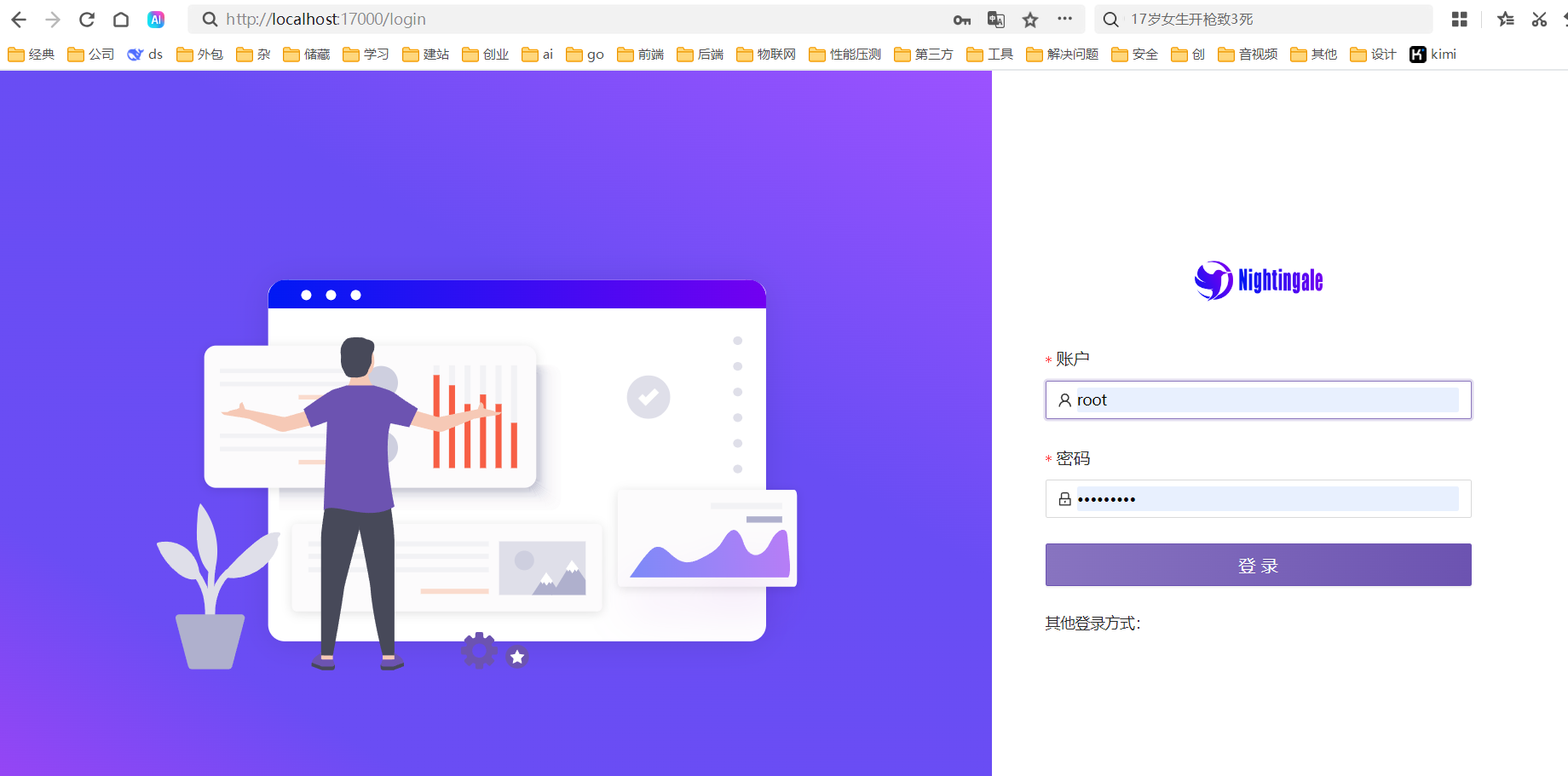
注:如果是win或本地运行,则需要修改下面两个文件中的地址为物理机地址才可以访问,如果新增其他服务,同样在这里新增个文件即可
- deploy/docker/conf/nightingale/etc-categraf/input.prometheus/core.toml
- deploy/docker/conf/nightingale/etc-categraf/input.prometheus/things.toml
夜莺配置
基础配置
- 数据源配置
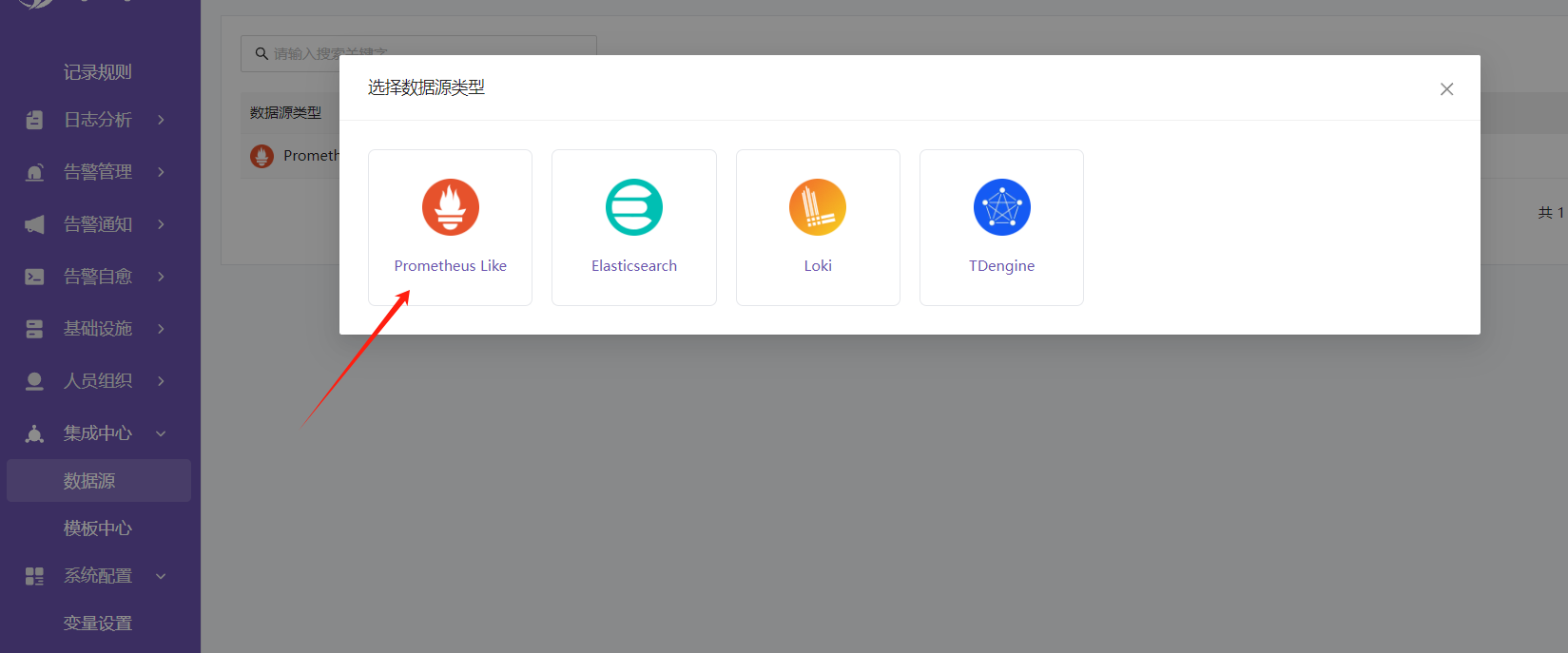
在url中填入: http://victoriametrics:8428/
然后确认即可
- 服务状态查看
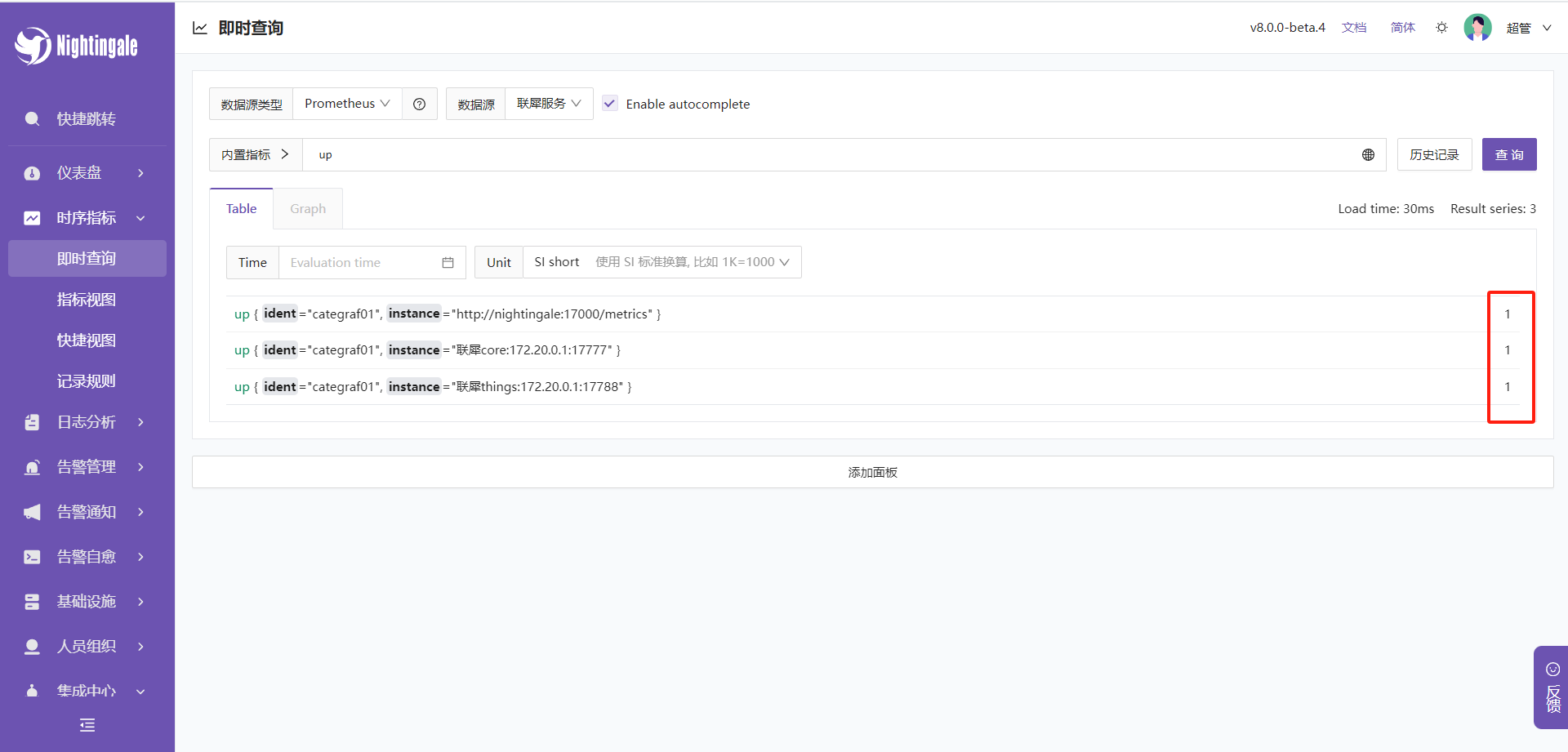
在时序指标-即时查询中输入up 可以看到三个服务,右边的参数都为1则为配置OK,如果为0,则需要看下是不是联犀的上报配置未打开或 deploy/docker/conf/nightingale/etc-categraf/input.prometheus/ 下的服务ip访问不到需要检查.
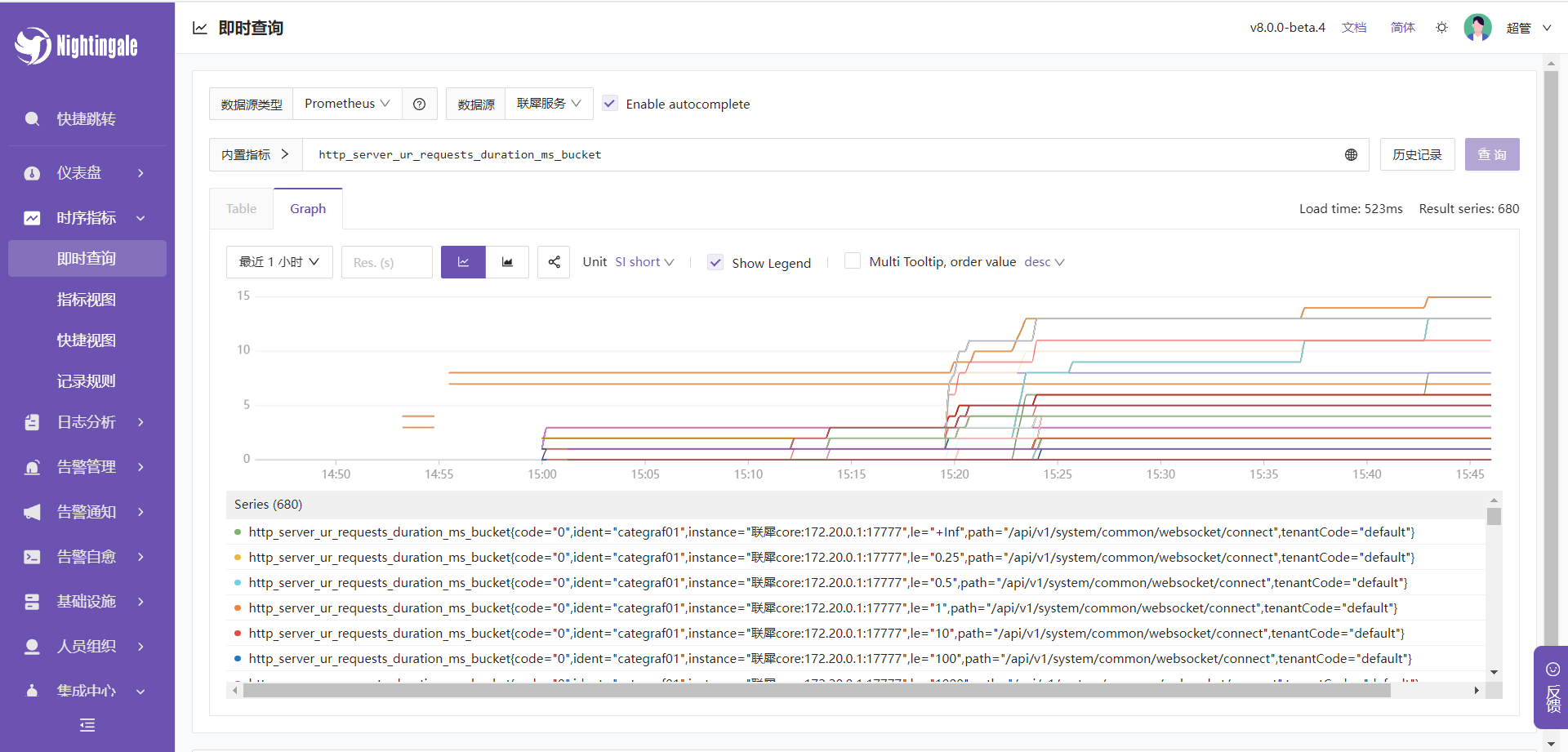
- 接口耗时查看
联犀会上报三个指标:
http_server_ur_requests_duration_ms_bucket
这是一个 直方图(Histogram) 指标的桶(bucket)部分。它记录了 HTTP 请求处理时间的分布情况。具体来说:
- 它将请求处理时间划分为多个区间(桶),每个桶对应一个时间范围。
- 每个桶的值表示处理时间小于或等于该桶上限的请求数量。
- 例如,
http_server_ur_requests_duration_ms_bucket{le="100"}的值为 100,表示处理时间小于或等于 100 毫秒的请求数量为 100。
http_server_ur_requests_duration_ms_count
这是一个 计数器(Counter) 指标,表示 HTTP 请求的总次数。它记录了所有 HTTP 请求的数量,无论这些请求的处理时间如何。通过这个指标,可以了解在特定时间段内服务处理的请求数量。
3.)http_server_ur_requests_duration_ms_sum
这是一个 计数器(Counter) 指标,表示所有 HTTP 请求处理时间的总和。它记录了所有 HTTP 请求的处理时间累加值,单位通常是毫秒。通过这个指标,可以计算平均请求处理时间
大屏和告警
大屏
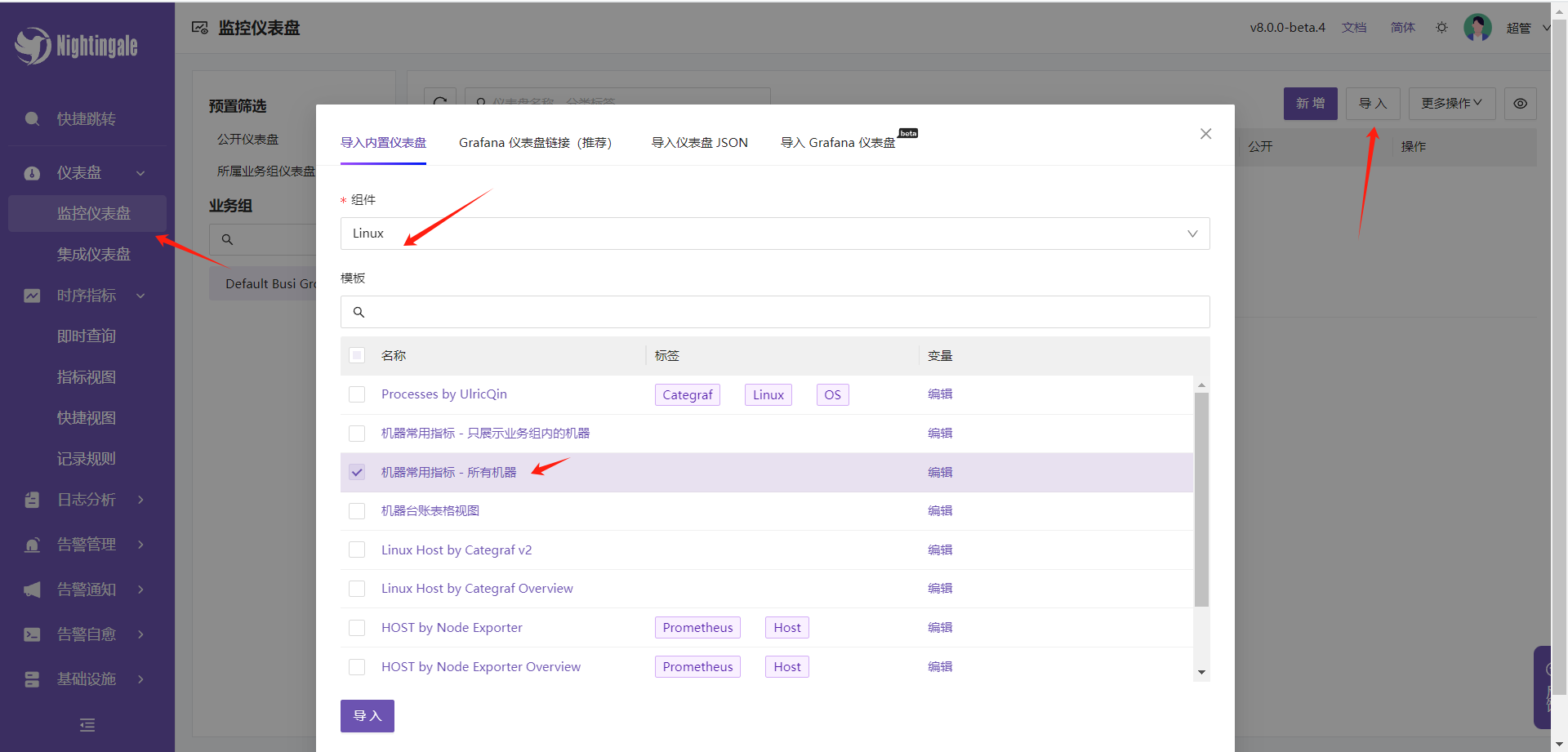
- 我们打开仪表盘-监控仪表盘,点击导入, 组件搜索linux,点击下面的机器炒年糕用指标-所有机器,点击导入
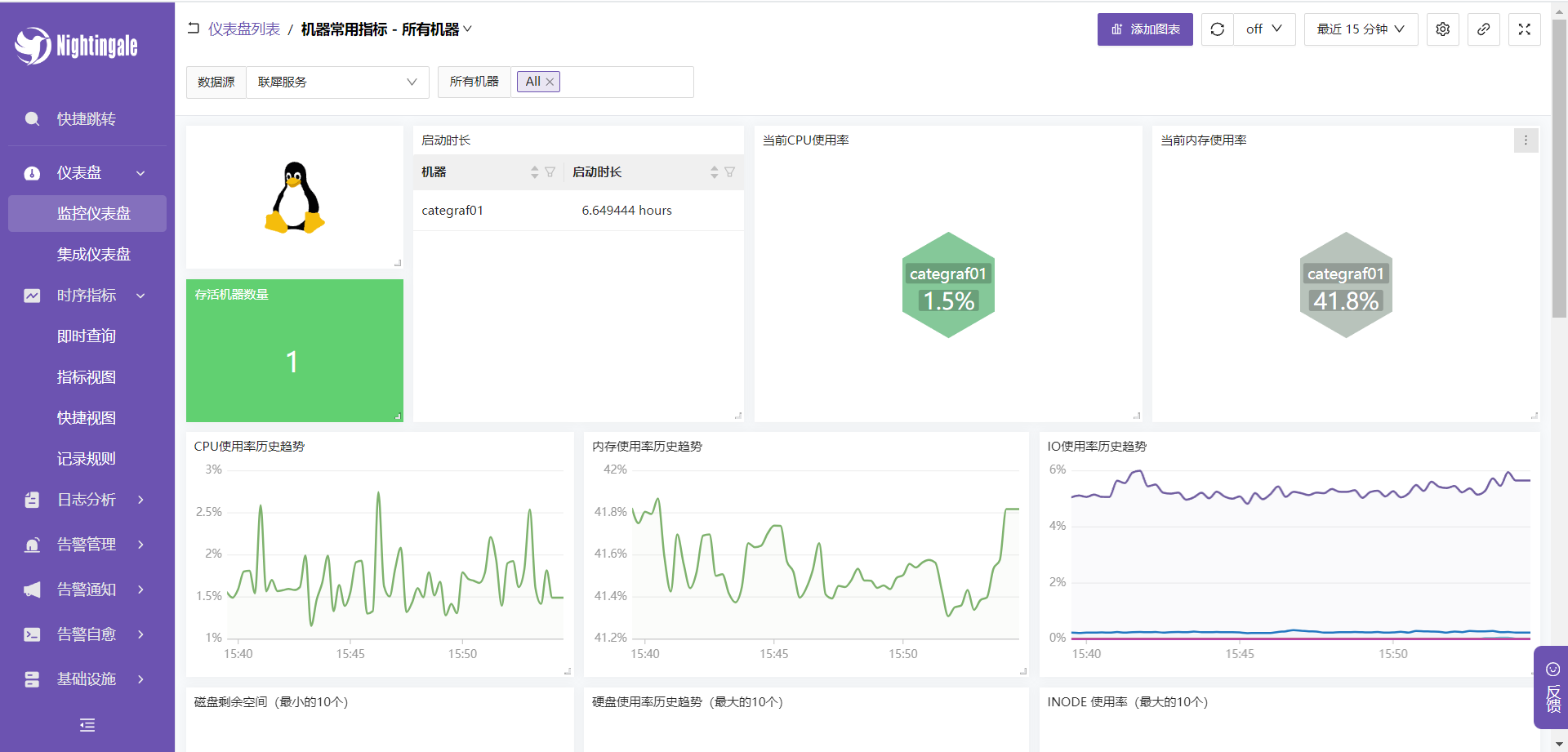
然后我们就可以看到系统监控信息了
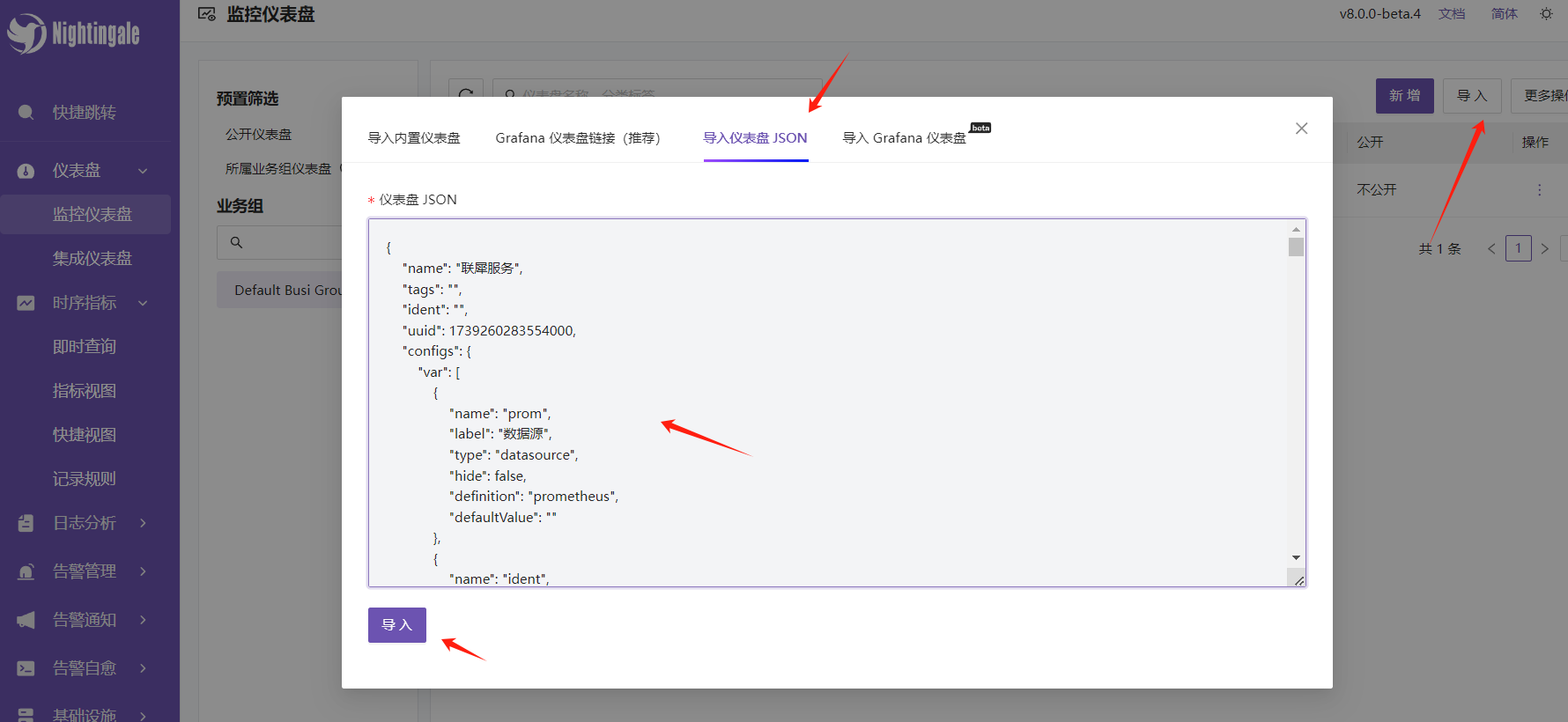
- 联犀服务监控导入(企业用户提供)
- 进入企业版文档,在运维资料中复制大屏配置文件json

- 在夜莺的导入-导入仪表盘中复制进去并导入
- 查看仪表盘
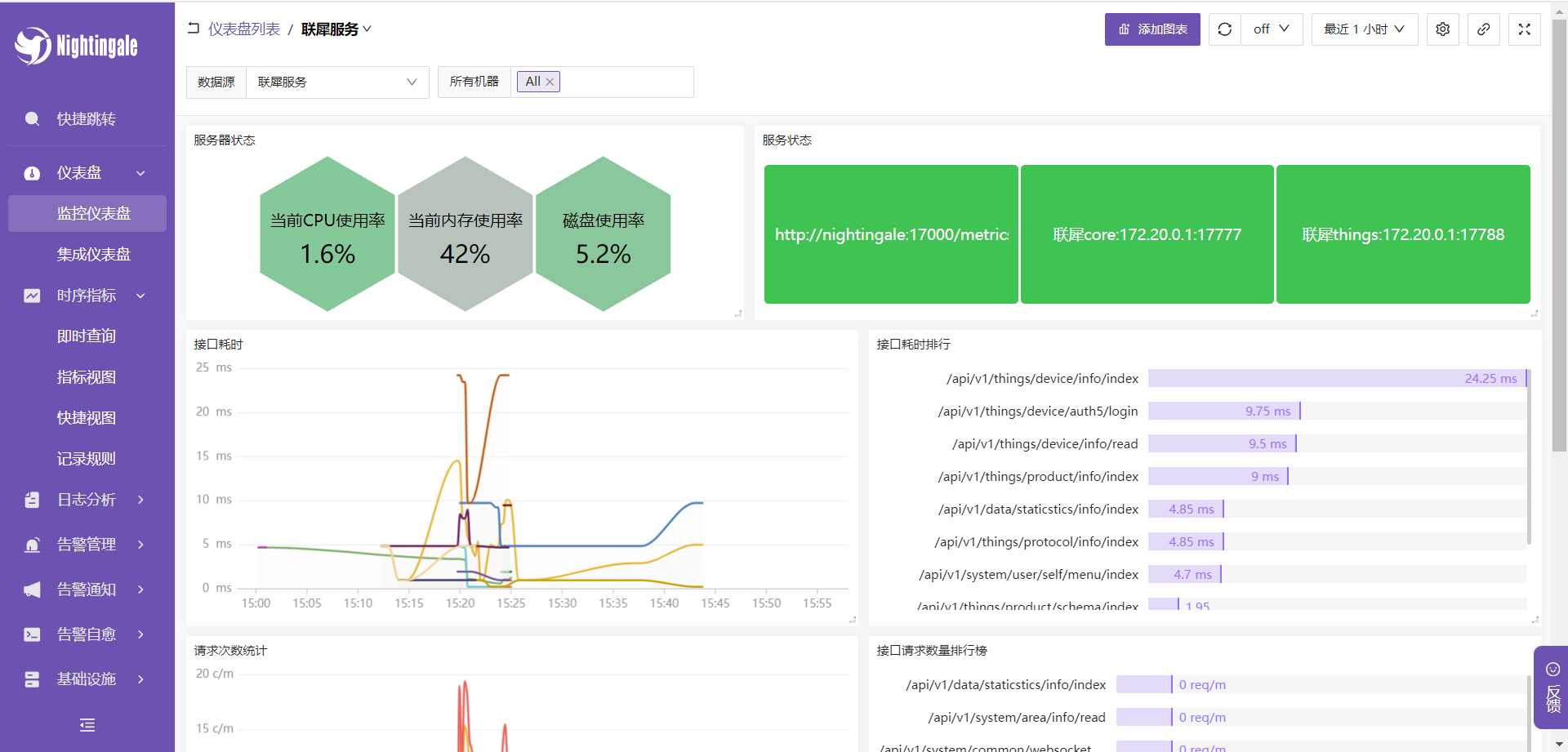
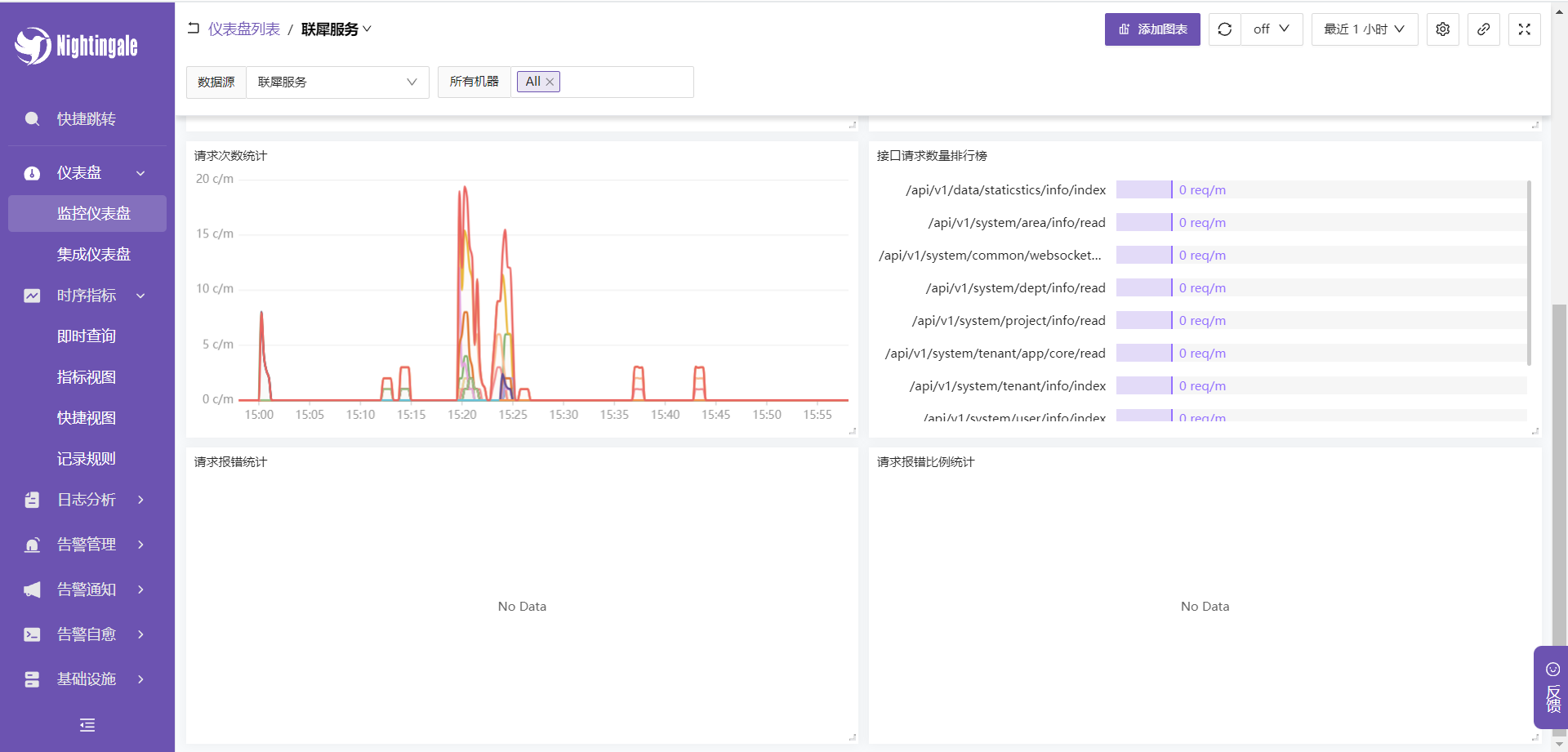
- 在联犀后台中查看仪表盘
- 在公开旁边有个编辑,点开后按图中选择后确定
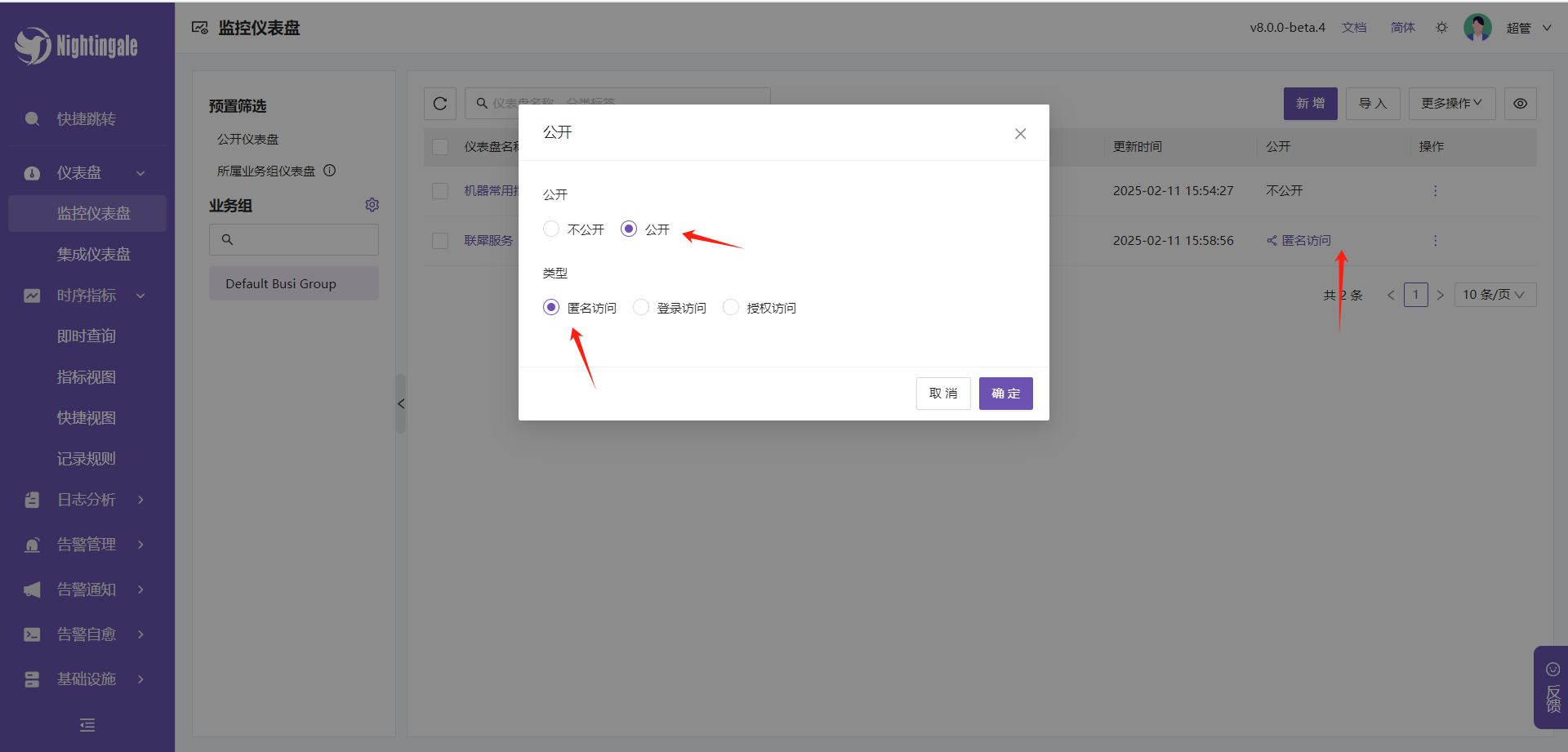
确认后公开这里会变成一个链接,我们复制这个链接,后面在联犀中使用
打开联犀后台 系统管理-平台管理-模块管理- 在系统管理右边点击操作
菜单类型改成iframe内嵌,菜单path改成devops,iframe页面地址则填写夜莺中复制的地址
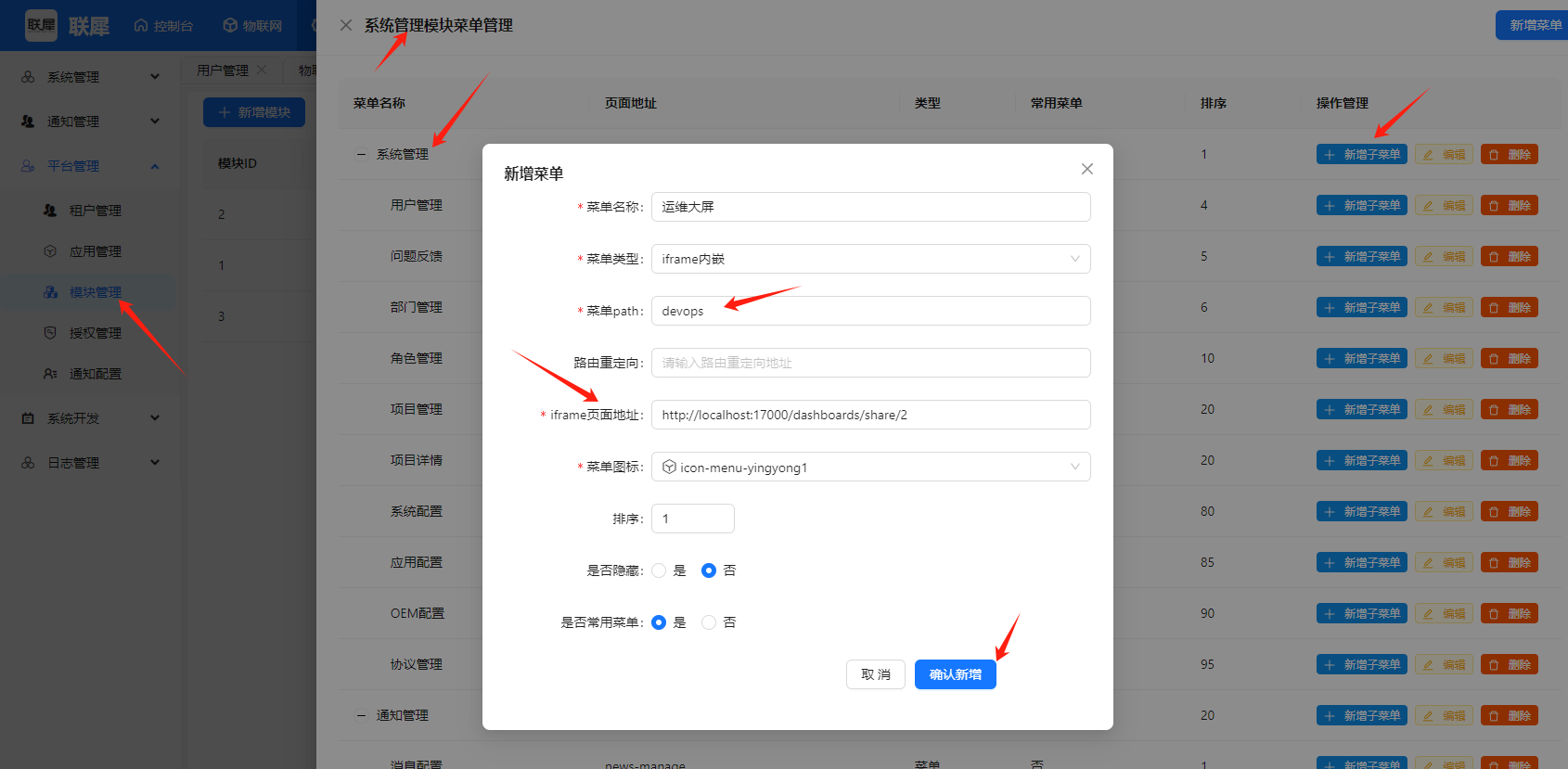
- 退出登录重登后查看大屏
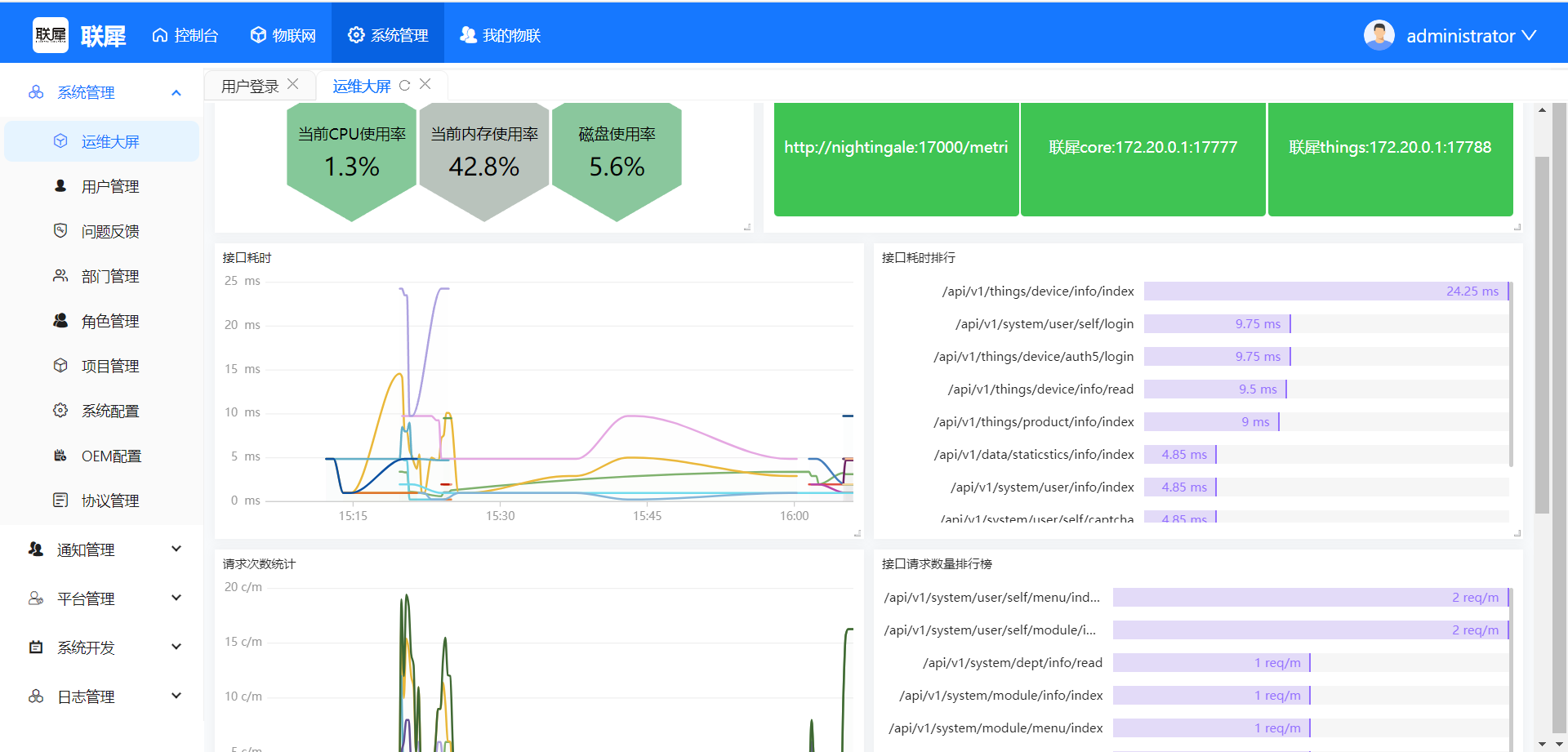
告警
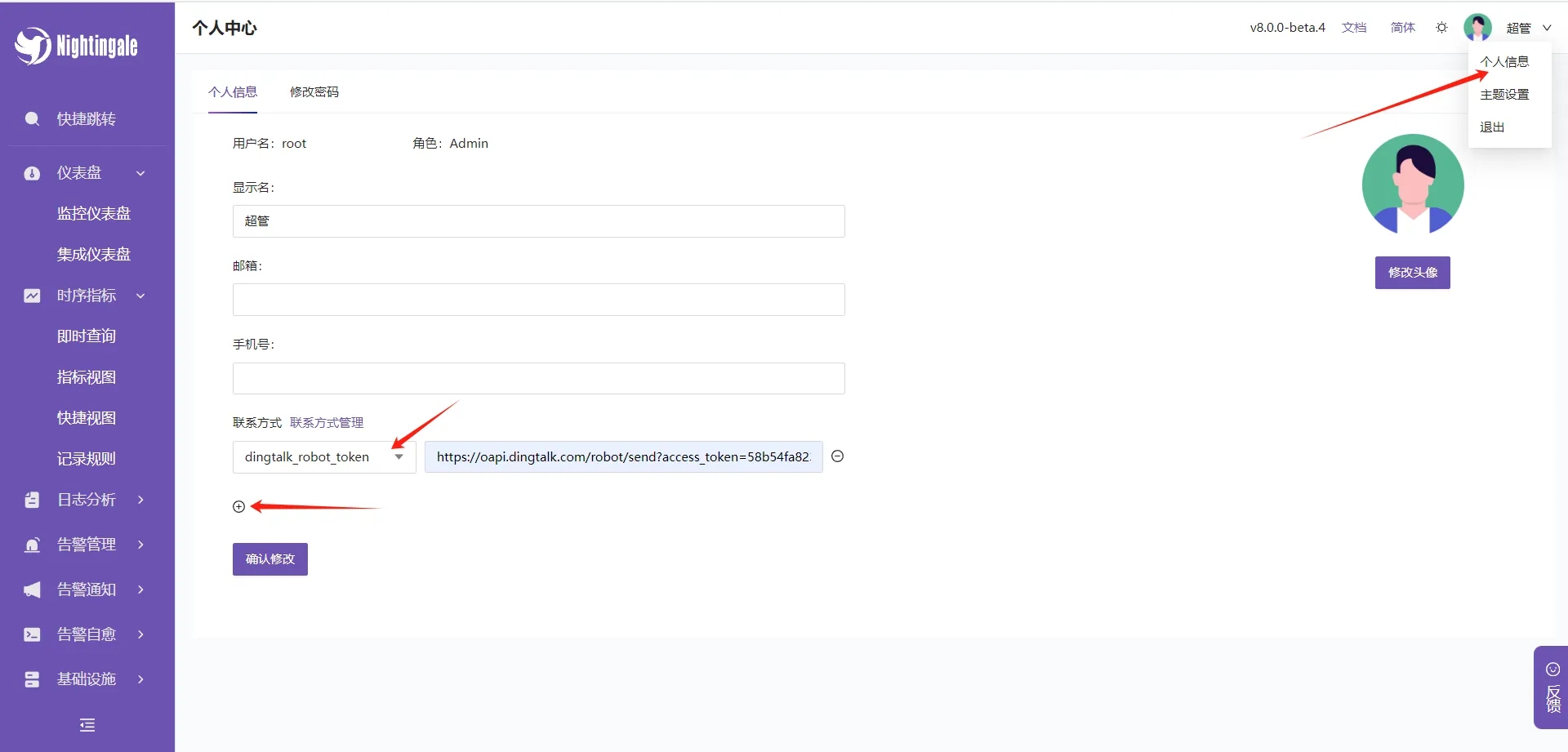
- 告警我们需要先配置好通知的信息
右上角点击个人信息,在个人信息下面有个+,可以填写企业钉钉,飞书等各种通知方式
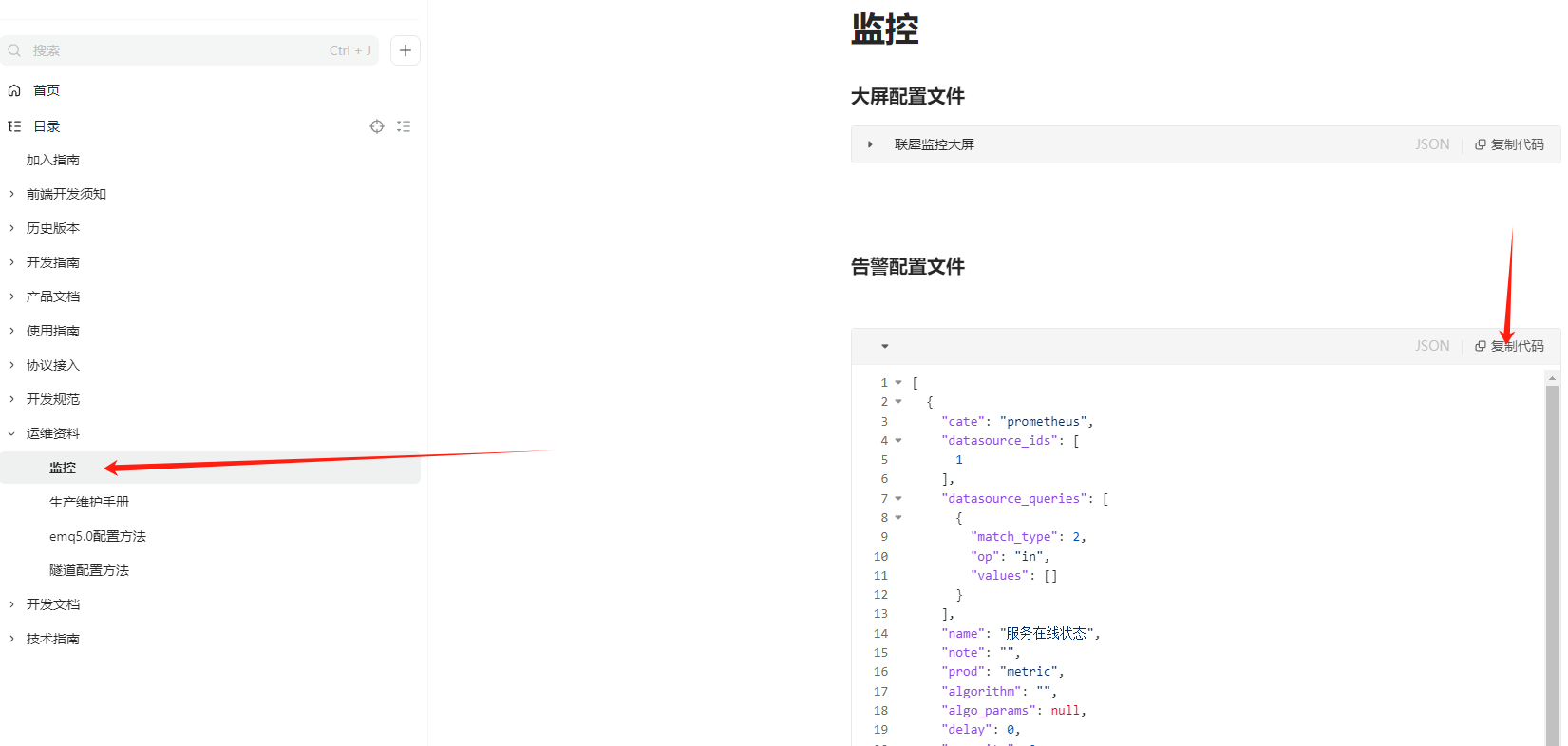
- 告警规则配置导入(企业版客户,开源用户可以自行创建)
- 打开企业版文档,复制告警配置json
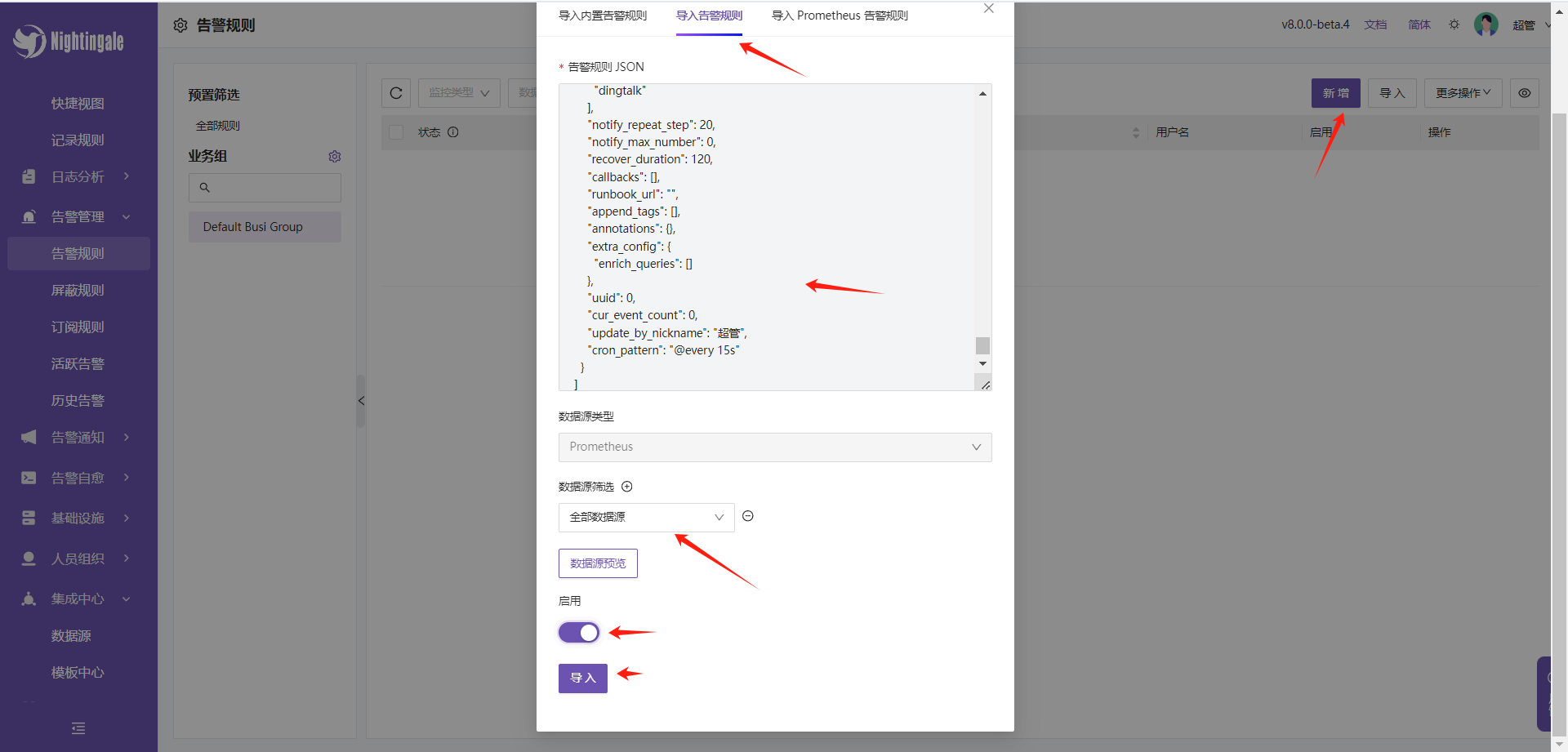
- 导入告警规则
告警管理-告警规则-导入-导入规则
注意: 数据源筛选选择全部数据源即可

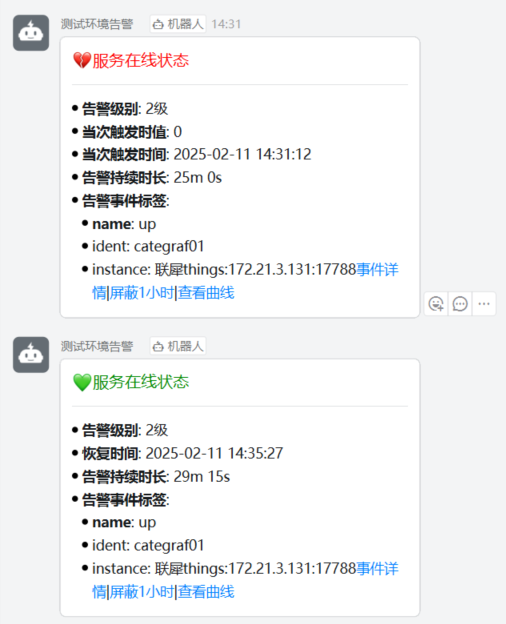
- 将服务down调测试通知
总结
至此我们就成功的借助夜莺实现了服务监控和告警的能力.
更新日志
2025/12/28 18:01
查看所有更新日志
bddea-于d4fa0-于45d7d-于
