为什么联犀选择 go-zero:goctl 代码生成、模板控制、monorepo 与融合式宿主的组合价值
对于小项目、小需求,让 AI 直接决定怎么写通常没有问题。代码量不大、模块不多、接口不复杂,AI 即使在没有严格约束的环境下,也能靠推理能力把功能做出来。反正简单,怎么开发都没事。
但当软件规模上来之后,基础架构的重要性就会急剧放大。它不是决定"能不能写",而是决定"AI 开发的效率高不高"。一个结构清晰、边界稳定、生成链路可控的代码库,能让 AI 把大部分 token 花在真正的业务差异上;而一个结构混乱、约束隐晦、上下文发散的代码库,会让 AI 反复在"猜项目规范"和"对齐工程习惯"上消耗算力,真正用于业务逻辑的推理时间反而被压缩。
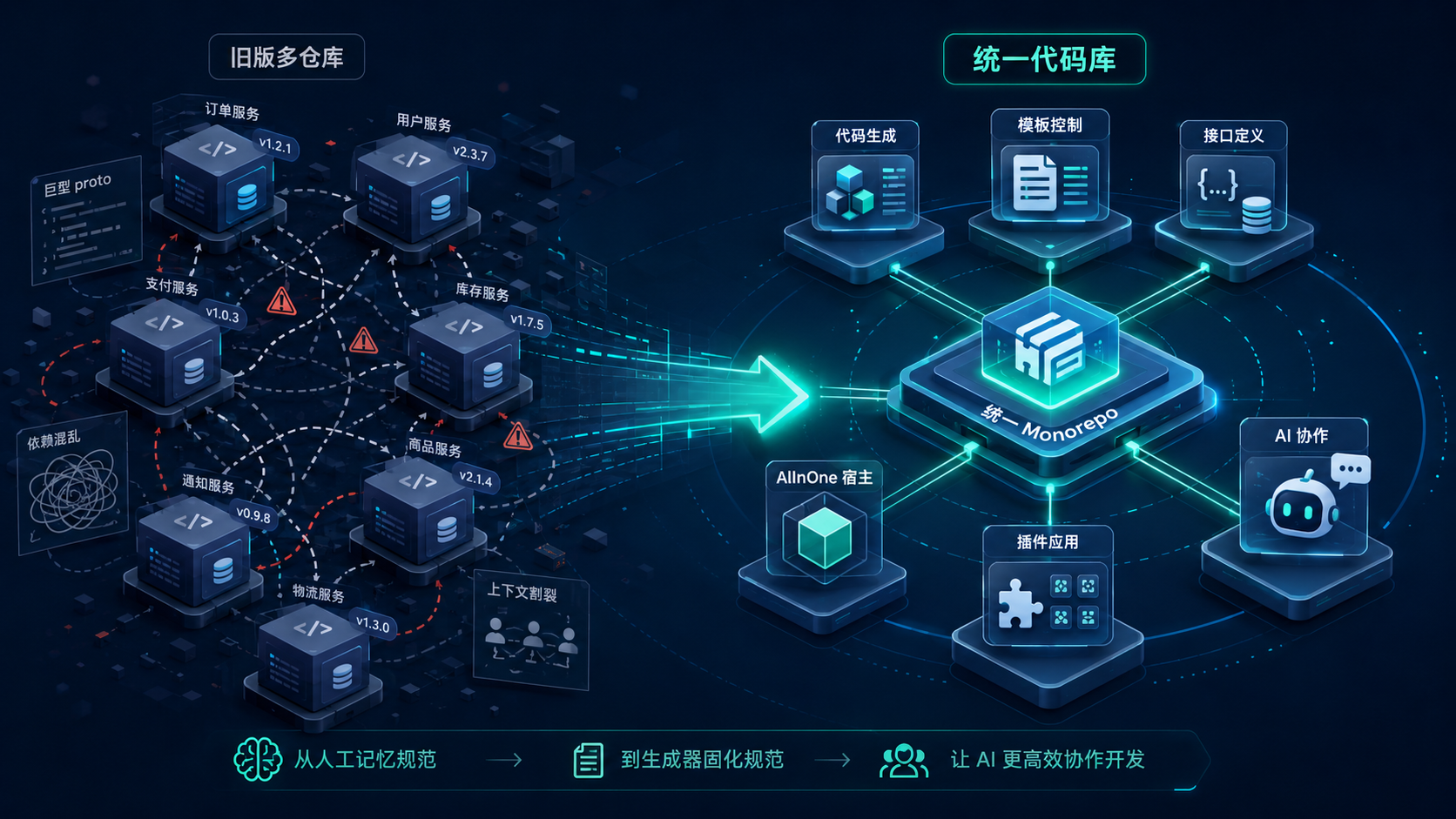
联犀对此有切身体会。在 2026 年 3 月之前的旧版架构中,联犀采用的是多仓库拆分模式:share、core、things、things-ee、app 五个独立 Go module,每个都有自己的 Git 仓库、自己的 tag 生命周期、自己的依赖链。tag 升级必须按 share -> core -> things -> things-ee -> app 的顺序逐个推进,任何跨模块的接口变更都需要在多个仓库间同步版本。更直接的问题是,旧版 dmsvr 的 RPC 定义只放在 3 个 .proto 文件里,其中 dm.proto 一个文件就有 2705 行——这意味着 AI 在处理设备管理相关需求时,必须在一个巨型文件里逐行扫描才能找到正确的接口定义,上下文成本极高。
正是因为旧版架构让 AI 很难完整释放生产力,联犀才在单仓合并时彻底重构了工程结构:把多仓库合并为 monorepo,把巨型 proto 按业务域拆成多个独立文件,把原本只能靠"人记住"的工程约束固化进 goctl 的模板和校验链路里。这些改动不是为了追求概念上的先进,而是为了让 AI 在联犀的代码库里能稳定、高效、持续地产出规范代码。
下面这篇文章,就是围绕这些工程选择展开的具体说明。
为什么是 go-zero,而不是只选一个"好用的 Go Web 框架"
如果系统只是做几个 HTTP 服务,很多 Go Web 框架都能胜任。
但联犀的目标更复杂。它同时要覆盖中台 API、物联网 API、RPC 服务、协议模块、AllInOne 宿主和若干共享基础能力。单纯的 Web 框架很难把这些边界一并组织好,最后很容易变成"服务能跑,但工程结构不断发散"。
go-zero 对联犀最大的价值,不是帮我们少写 handler,而是把"接口定义驱动代码结构"这件事做得足够彻底。
API 可以通过 .api 文件描述,RPC 可以通过 .proto 文件描述,生成代码后,handler、logic、service context、client 等结构天然分层。这样一来,系统的骨架不是靠团队成员自己临场决定,而是从定义文件开始就被固定下来。
对于长期维护的 monorepo 来说,这一点非常关键。因为真正昂贵的不是初次开发速度,而是几年之后还能不能持续保持统一风格。
goctl 的真正价值不是"省点样板代码"
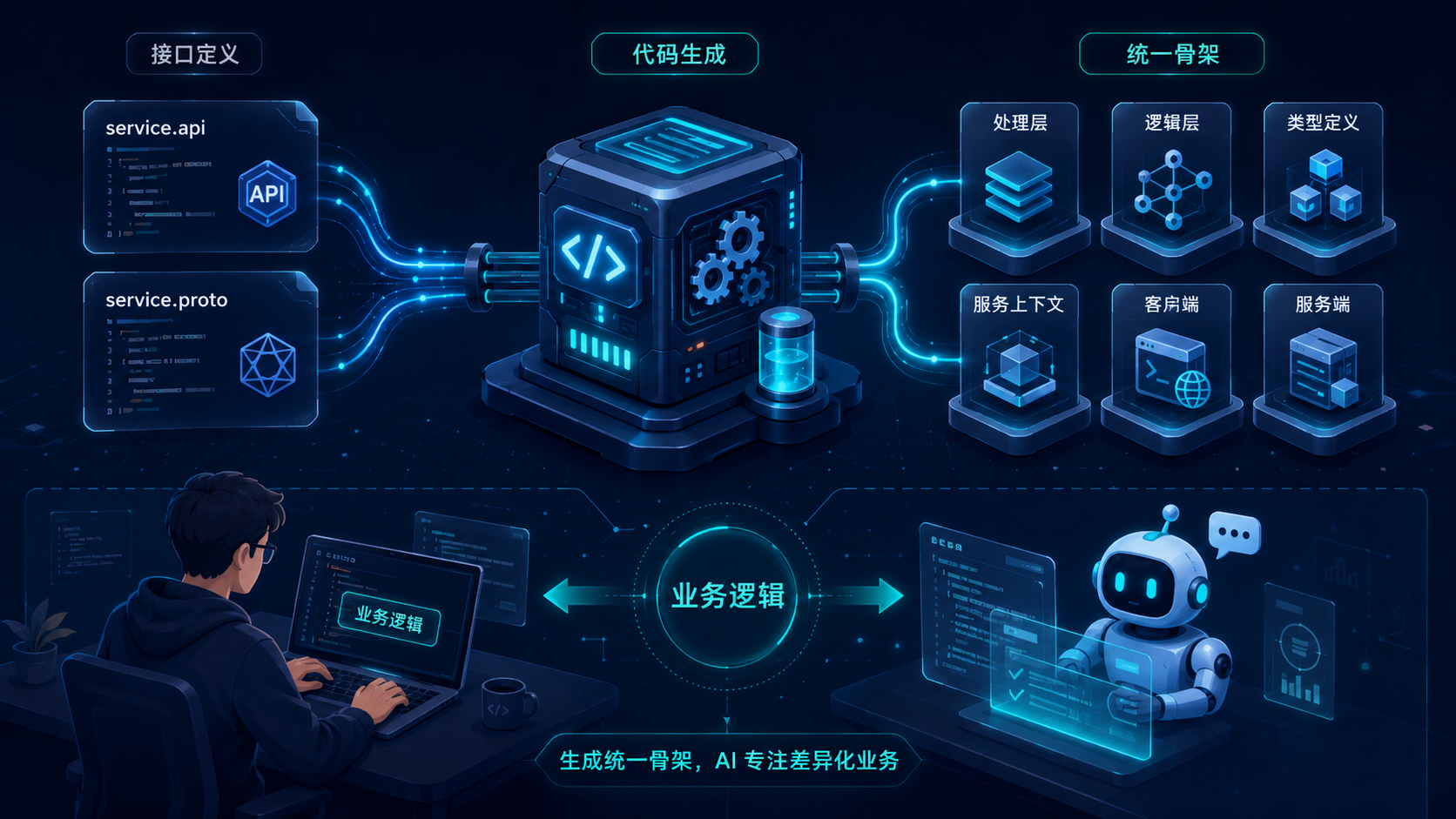
很多团队提到代码生成时,理解还停留在"少写点重复代码"。这当然是收益之一,但不是联犀最看重的部分。
在联犀里,goctl 更像是一套结构约束工具。
它把接口定义、目录组织和生成结果捆在一起,让很多本来容易漂移的工程约束变成了默认路径。
例如:
- 新增 API 服务时,入口、handler、logic、types 的骨架是统一的
- 新增 RPC 服务时,client、server、logic 的分层是统一的
.api和.proto成为对外契约,而不是代码实现之后再回头补文档
这意味着新增一个服务,不需要每个人都重新思考"目录怎么摆、命名怎么定、接口怎么拆层",而是直接沿着统一骨架前进。
在 AI 编码场景下,这种收益会被进一步放大。
AI 最大的问题通常不是不会写代码,而是当上下文太散、结构太自由、隐性约束太多时,它很容易在"局部看起来合理、全局却不一致"的方向上持续输出。goctl 提供的统一骨架,等于把很多原本只能靠人口口相传的约束,提前变成了生成结果本身。这样 AI 不是在一块完全开放的空地上自由发挥,而是在一个结构已经被稳定下来的工地里继续施工。
联犀为什么一定要用定制版 goctl
如果只是使用官方模板,很多系统也能跑起来。但联犀并不是一个只满足于"能生成代码"的项目。我们需要的是让生成结果贴合自己的架构,而不是让架构去迁就生成器。
因此联犀在实践中采用了定制版 go-zero / goctl,源码维护在 https://gitee.com/unitedrhino/go-zero,并对模板进行了控制。
这样做的原因很现实:
1. API 与 RPC 代码要贴合联犀自己的约束
联犀有自己固定的接口设计规范,例如:
- API 全部使用
post .api顶层聚合文件统一引入common.api@doc中必须显式标注权限、资源、动作和日志模式- 每个接口必须写
summary和description,作为 AI 认知接口用途的第一手材料
这些约束如果只靠"团队自觉遵守",时间长了一定会松。放进生成和校验链路里,反而更稳。
2. 生成结果要适配直连与融合式宿主
联犀不是纯远程 RPC 世界。
在很多服务里,同一套接口需要同时支持 grpc client 和 direct 调用。模板控制的价值,就在于让这类结构成为标准产物,而不是每个服务手工重复一遍。
3. 代码生成还承担了质量闸门作用
例如 goctl api swagger 在联犀里不仅是导出文档,更承担了接口元数据校验角色。
缺字段、值非法、权限说明不完整、接口描述缺失时,直接在生成阶段报错,比代码上线后再靠 review 补救要靠谱得多。
模板控制为什么对平台型项目特别重要
模板控制这件事,对单个小项目未必值当,但对联犀这种平台型 monorepo 非常重要。
原因在于,平台型项目不是只做一个服务,而是会不断新增:
- 中台服务
- 物联网服务
- 协议模块
- 应用子模块
如果生成骨架不受控,不同模块很快就会长成不同风格。
一开始看似只是"多了几个自由度",最后往往演变成:
- 相似服务结构不一致
- 逻辑层和适配层职责混杂
- 新同学 onboarding 成本上升
- 自动化脚本、review 规则和运维流程越来越难统一
而模板一旦被控制住,很多组织性成本会前置一次性解决。
对 AI 编码来说,模板控制还有一个额外价值:它能显著减少"同类问题每次都要重新解释"的成本。
如果团队每次都需要告诉 AI:
- handler 应该只做解析,logic 才放业务
- 哪些字段必须出现在接口定义里
- 哪种 client 需要同时支持 grpc 和 direct
- 哪些注释、命名、返回结构才算项目规范
那么 AI 看似在写代码,实际上大量 token 都花在重新对齐项目习惯上。模板被控制住之后,很多规范不再需要在 prompt 里反复强调,而是直接体现在生成骨架里。AI 只需要聚焦当前差异化逻辑,而不是反复学习同一套项目纪律。
monorepo:从多仓库困境到统一代码库

前面提到联犀旧版是多仓库架构,每个模块独立 Git 仓库、独立 tag、独立依赖链。这种模式在团队规模较小时可以运转,但当 AI 开始深度参与编码后,问题被放大了:
- 跨仓库上下文断裂:AI 处理一个需求时,往往只能看到当前仓库的代码,看不到依赖模块的接口定义和实现细节,只能靠猜测推断系统行为
- tag 升级成本高:修改一个跨模块的接口,需要按
share -> core -> things -> things-ee -> app的顺序逐个打 tag、更新依赖、验证兼容性,AI 很难在一次会话内完成这种跨仓库协调 - 巨型 proto 文件:旧版
dmsvr的dm.proto一个文件 2705 行,包含设备管理、产品管理、OTA、场景联动等所有接口,AI 定位具体业务域时上下文成本极高
联犀的解决方案不是继续修补多仓库,而是彻底转向 monorepo。
Go Workspace 如何组织模块边界
联犀后端现在采用 Go Workspace 组织多个模块。core 负责 SaaS 中台与 AI 中台能力,things 负责物联网平台能力,share 负责公共基础库,mall 负责商城相关能力,apps/prepaid 等作为独立应用模块接入。
这层分法的重点不在"模块数量",而在职责边界:share 作为底层公共层,不依赖 core 或 things;core 和 things 则在上层按业务域组织能力。
backend/
├── cmd/
│ └── allInOne/ # 一体化宿主入口
├── core/
│ ├── cmd/
│ ├── service/
│ │ ├── apisvr/
│ │ ├── syssvr/
│ │ ├── datasvr/
│ │ ├── aisvr/
│ │ └── timedsvr/
│ └── share/
├── things/
│ ├── cmd/
│ ├── service/
│ │ ├── apisvr/
│ │ ├── dmsvr/
│ │ ├── udsvr/
│ │ ├── aisvr/
│ │ ├── cardsvr/
│ │ ├── lowcodesvr/
│ │ └── viewsvr/
│ └── share/
├── share/
│ ├── clients/
│ ├── ctxs/
│ ├── eventBus/
│ ├── events/
│ ├── stores/
│ └── utils/
├── protocol/
│ ├── modbus/
│ ├── aliyun-mqtt/
│ ├── xiaozhi/
│ └── ...
├── apps/
│ └── prepaid/ # 可插拔应用模块
├── mall/
└── go.work对 AI 来说,这种结构的意义非常大。它不是面对一个"所有代码都堆在一起的大仓库",而是面对一个有稳定模块层级、稳定共享层和稳定服务骨架的大仓库。
monorepo 让跨模块协同更自然
share 作为底层公共层,承载上下文、缓存、事件、存储、基础客户端等能力。core 和 things 在其上组合服务。
在 monorepo 里,这种共享是稳定且可见的;如果拆成多个仓库,公共层版本治理、跨仓演进和生成骨架同步都会麻烦很多。
同时,.api、.proto、生成客户端、服务实现、文档和测试都在同一代码库里。这让"改接口 -> 生成代码 -> 修实现 -> 跑校验"的闭环非常顺畅,也更适合高频迭代的中台和物联网场景。
AI 时代,monorepo 为什么反而更适合"让 AI 专注"
很多人会直觉认为,仓库越大,AI 越难工作,所以 monorepo 对 AI 不友好。这个判断只说对了一半。
如果 monorepo 没有边界、没有模块纪律、没有统一骨架,那它当然会让 AI 很痛苦,因为上下文一展开就是整片代码海洋,模型既不知道该看哪里,也不知道哪些约束是全局性的。
但联犀这种带有清晰模块边界的 monorepo,反而更适合 AI 参与开发,原因恰恰在于"既大,又能局部聚焦"。
第一,AI 可以先锁定具体模块,再锁定具体服务。core、things、share、protocol 的边界清晰之后,AI 不需要一上来吞下整个仓库。它完全可以先判断当前问题属于哪个模块,再继续缩小到具体服务、具体接口、具体逻辑目录。这样上下文裁剪会自然很多,模型也更容易把注意力放在真正相关的那部分代码上。
例如:
- 权限、Hook、WebSocket 相关问题,大概率先落在
core/service或core/share - 设备接入、MQTT、时序仓储问题,大概率先落在
things/service/dmsvr - 公共上下文、事件封装、基础存储能力,优先看
share - 协议厂商适配问题,优先看
protocol/*
对 AI 来说,最昂贵的不是代码量本身,而是无效上下文。清晰的 monorepo 结构,等于给了它一张可靠地图,让它可以逐层收缩搜索范围,而不是每次都从零开始全仓猜测。
第二,公共能力在一个仓里,AI 更容易看清真实约束。
如果一个平台拆成很多仓库,AI 在处理某个服务时,往往看不到真正的共享层实现、上下文工具、公共错误模型和事件封装方式,只能凭局部信息猜测系统约束。而在 monorepo 里,share 层、公共 client、统一上下文、基础中间件都和业务代码在同一仓库中。AI 更容易看到"这个系统真实是怎么写的",而不是只看某个局部入口文件。
第三,monorepo 让 AI 更容易做"局部修改,不扩散重构"。
联犀这种结构下,模块边界和目录职责都比较稳定,AI 更容易判断哪些地方是本次任务真正应该动的,哪些地方只是相关背景。这对于控制改动范围特别重要。因为 AI 一旦看不清边界,就很容易做出"顺手优化一片"的扩散式修改。
清晰的 monorepo,不是让 AI 看更多,而是让 AI 更容易知道"不该看什么、不该改什么"。
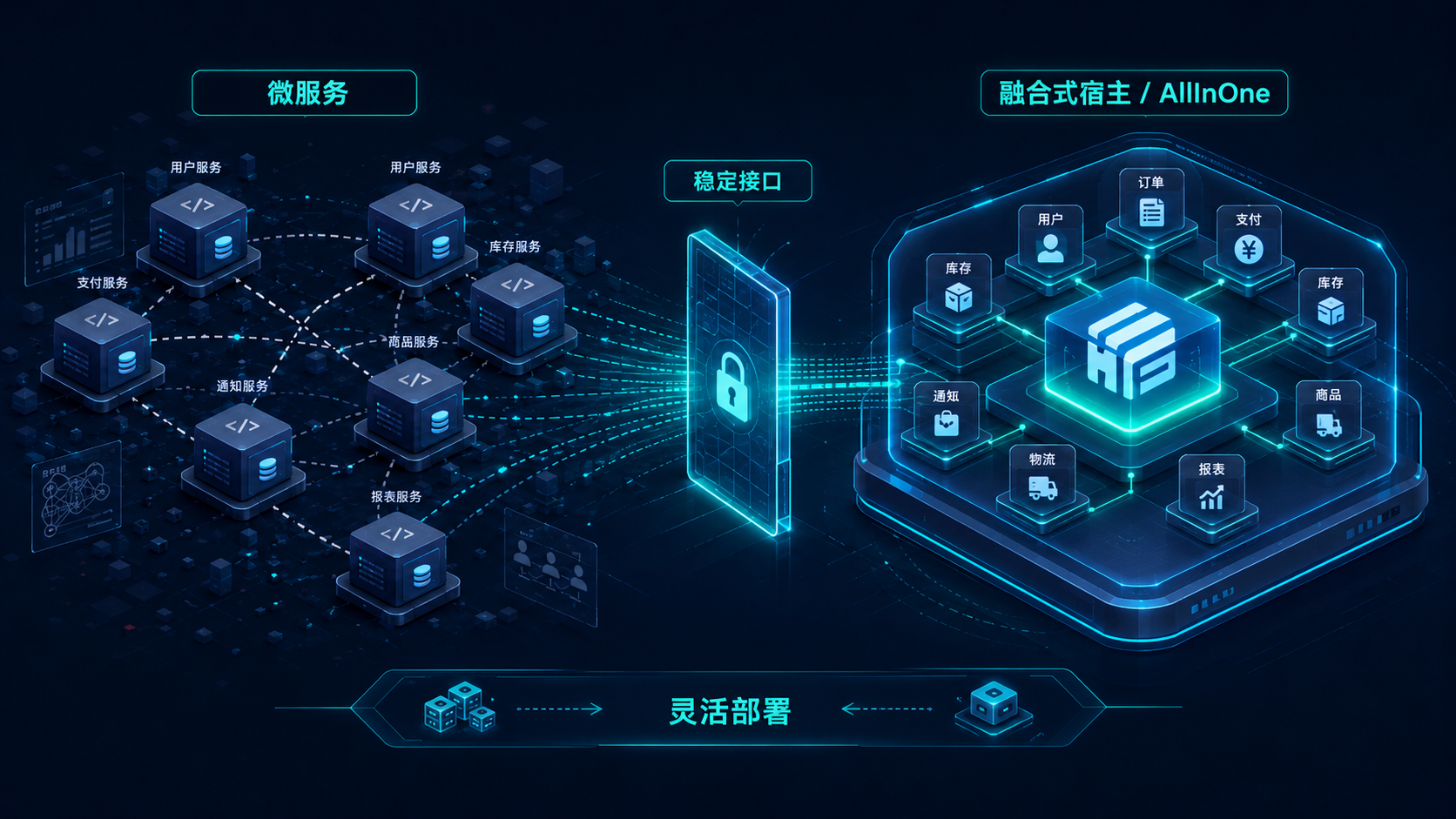
微服务、融合式宿主与 AllInOne:灵活的部署选择
很多团队在后端架构上都会遇到同一个矛盾。
业务早期希望部署简单、成本低、调试方便,最好一套服务就能把系统跑起来;但业务一旦增长,又希望服务可以独立扩缩、独立演进、按模块拆分,不要所有能力都绑死在一个进程里。
问题从来不在于"单体好还是微服务好",而在于系统一开始怎样设计,才能不把自己锁死在某一种部署形态里。
联犀当前的答案不是在两者之间摇摆,而是把"业务边界""调用方式"和"部署方式"拆开看。业务边界应该稳定,调用接口应该稳定,但部署形态可以随阶段变化。
单体和微服务真正的问题分别是什么
很多人对单体架构的误解,是把它等同于"简单"。实际上,单体最大的风险不是服务少,而是边界模糊。只要业务逻辑、数据访问、上下文传递和公共能力全都搅在一起,后期想拆分时,代价往往比重写还高。
而纯微服务路线的问题也不是"太先进",而是它把很多成本前置了。服务数量、网关数量、配置数量、部署复杂度、跨服务调试成本,都会在业务还没长起来之前先压到团队头上。对于 SaaS + IoT 这类既有中台能力又有设备链路能力的系统,这种过早拆分尤其容易把本来应该靠近的数据和逻辑人为拉远。
所以真正该避免的,不是某一种架构名词,而是把业务边界直接绑到某一种固定部署模型上。
融合式宿主不是退回单体
很多人第一次看到"融合式宿主"会误以为这只是换个说法回到单体。其实不是。
融合式宿主的前提是:服务边界、协议边界和接口边界仍然存在,只是在运行时让高耦合、高吞吐、同链路的能力靠得更近,以减少无意义的跨进程跳转。
物联网侧的 dmsvr 就是一个很典型的例子。它不再只是狭义上的"设备管理服务",而是承载了设备管理、网关主链路、MQTT 宿主、协议脚本运行时和时序仓储等能力。
这类能力之所以适合统一宿主,不是因为"偷懒不拆",而是因为它们本身就共享上下文、共享设备链路、共享高频数据流。如果为了追求形式上的微服务纯度把它们机械拆开,最终只会把延迟、复杂度和调试成本全部抬上去。
为什么这种方式对联犀更合适
联犀既不是单纯的企业管理后台,也不是只有设备接入的窄场景网关,它同时要处理:
- SaaS 中台的用户、权限、租户、应用、通知、定时任务
- 物联网侧的设备管理、项目区域、协议脚本、MQTT、时序数据
- AI 侧的 Agent、记忆、MCP、设备交互
这些能力之间不是完全松散的。很多跨域调用其实是高频、短路径、强上下文耦合的。如果全部强制走远程服务调用,代价很高;但如果全部塞回一个完全无边界的大进程里,后期又无法演进。
联犀选择的路线,本质上是在这两种坏结果之间取一个工程上更稳的中间态:边界明确,但运行方式灵活。
柔性部署的前提不是"服务少",而是"接口稳"
这也是联犀后端设计里最关键的一点。真正让系统既能微服务、又能融合部署的,不是目录怎么摆,而是接口是否稳定。
联犀当前大量能力对上层暴露的是稳定接口,而具体实现既可以是 grpc 客户端,也可以是进程内 direct 调用。这样一来,业务层关心的是"调用哪个能力",而不是"这个能力现在到底运行在本进程还是另一个进程里"。
只要这一层稳定,部署模式就不再决定业务代码长什么样。这也是联犀能把微服务模式、AllInOne 模式和融合式宿主模式放在同一套代码体系里,而不是做三套实现。
AllInOne 模式:一套代码,两种部署
上面说了"接口稳"是前提,但具体怎么做到同一套代码既能微服务又能 AllInOne?联犀的做法可以拆成两层来看:API 层的统一路由注册,和 RPC 层的直连调用切换。
为什么要这么做
对于 SaaS + IoT 平台来说,客户场景差异很大。有些客户只有几十台设备,希望一台 2C 4G 的机器就能跑起来;有些客户有几十万台设备,需要按模块独立扩缩容。如果为这两种场景维护两套代码,任何功能迭代都要改两次,很快就会出现"AllInOne 版本功能滞后"或"两边行为不一致"的问题。
联犀的选择是:代码只写一套,部署时按需选择模式。业务早期用 AllInOne 降低运维成本,业务增长后按模块拆成微服务,整个过程中业务代码不需要重写。
API 层:通过注册机制把多个服务的路由收敛到一个进程
在 AllInOne 模式下,联犀通过 services.RegisterApisvr 把各个业务域的 API 路由注册到同一个 rest.Server 里:
// backend/cmd/allInOne/main.go
func main() {
Init() // 注册 things 侧服务
apiCtx := coreExport.NewApi(coreExport.ApiCtx{}, "")
services.InitApisvrs(apiCtx.Server) // 把已注册的所有路由挂载到同一个 server
apiCtx.Server.Start()
}svc_core.go 和 svc_things.go 在 init 阶段完成注册:
// backend/cmd/allInOne/svc_core.go
func init() {
aisvrExport.Register() // 注册 AI 服务路由
// ... 其他 core 服务注册
}
// backend/cmd/allInOne/svc_things.go
func Init() {
eeExport.Register() // 注册 things API 路由
lowcodeExport.Init() // 注册低代码服务
viewExport.Init() // 注册可视化服务
}每个服务的 Register() 内部通过 services.RegisterApisvr 把自己挂载到全局注册表:
// backend/core/service/apisvr/coreExport/run.go
func Register() {
services.RegisterApisvr(func(server *rest.Server) error {
once.Do(func() {
NewApi(ApiCtx{Server: server}, "")
})
return nil
})
}这意味着:微服务模式下,core/apisvr 和 things/apisvr 各自启动独立的 HTTP server;AllInOne 模式下,它们的路由被注册到同一个 server 里,对外只暴露一个端口。
RPC 层:通过 goctl 生成的直连客户端跳过网络跳转
API 层解决了"入口统一"的问题,但服务内部还有大量 RPC 调用。如果 AllInOne 模式下仍然走 gRPC 网络调用,那就只是"把多个进程塞进一个容器",并没有减少实际的跨服务开销。
联犀的做法是:goctl 生成代码时,同时为每个 RPC 服务生成两套 client——一套走 gRPC(defaultDeviceInteract),一套走进程内 direct 调用(directDeviceInteract):
// goctl 生成的 client/deviceinteract/deviceInteract.go
func (m *defaultDeviceInteract) ActionSend(ctx context.Context, in *ActionSendReq, opts ...grpc.CallOption) (*ActionSendResp, error) {
client := dm.NewDeviceInteractClient(m.cli.Conn())
return client.ActionSend(ctx, in, opts...)
}
func (d *directDeviceInteract) ActionSend(ctx context.Context, in *ActionSendReq, opts ...grpc.CallOption) (*ActionSendResp, error) {
return d.svr.ActionSend(ctx, in) // 直接调用 server 实现,不走网络
}在 AllInOne 模式下,dmdirect 包负责初始化直连客户端:
// backend/things/service/dmsvr/dmdirect/deviceInteract.go
func NewDeviceInteract() client.DeviceInteract {
svcCtx := GetSvcCtx()
RunServer(svcCtx)
dmSvr := client.NewDirectDeviceInteract(svcCtx, server.NewDeviceInteractServer(svcCtx))
return dmSvr
}这里的关键是:NewDirectDeviceInteract 直接把 server.NewDeviceInteractServer(svcCtx) 塞给 client,client 调用时直接走 svr.ActionSend(ctx, in),完全跳过了 gRPC 序列化、网络传输和反序列化。对业务代码来说,它仍然像调用一个普通 client 方法,但底层已经从"远程调用"变成了"本地函数调用"。
配置层:通过 Mode 切换决定走 grpc 还是 direct
联犀在配置中通过 Mode 字段控制调用方式:
// backend/share/conf/rpcClient.go
ClientModeDirect = "direct"
// 配置示例
DmRpc:
Mode: direct // AllInOne 模式:进程内直接调用
Conf:
Target: 127.0.0.1:7540
// 或
DmRpc:
Mode: grpc // 微服务模式:通过 gRPC 远程调用
Conf:
Target: 127.0.0.1:7540这意味着同一套业务代码,只需要改配置文件里的 Mode 字段,就能在"微服务"和"AllInOne"之间切换,不需要改任何一行业务逻辑。
goctl 在这其中起了什么作用
如果没有 goctl,上述模式很难稳定维持。因为:
- goctl 为每个 RPC 服务同时生成 grpc client 和 direct client,开发者不需要手写两套调用代码
- goctl 生成的 server 接口是统一的,无论是远程调用还是直连调用,最终都是调用同一个
server实现 - goctl 生成的代码结构稳定,AI 或新成员不需要理解"为什么这个服务有两种调用方式",只需要按统一模式使用 client 即可
- 模板控制保证了生成结果的一致性,不会出现"这个服务有 direct client,那个服务没有"的情况
换句话说,goctl 不只是生成代码,它把"微服务 vs 单体"这个架构层面的选择,降级成了"配置层面的选择"。业务代码不需要感知自己运行在哪种模式下,这才是 AllInOne 和微服务能够共存的关键。
多应用的可插拔扩展
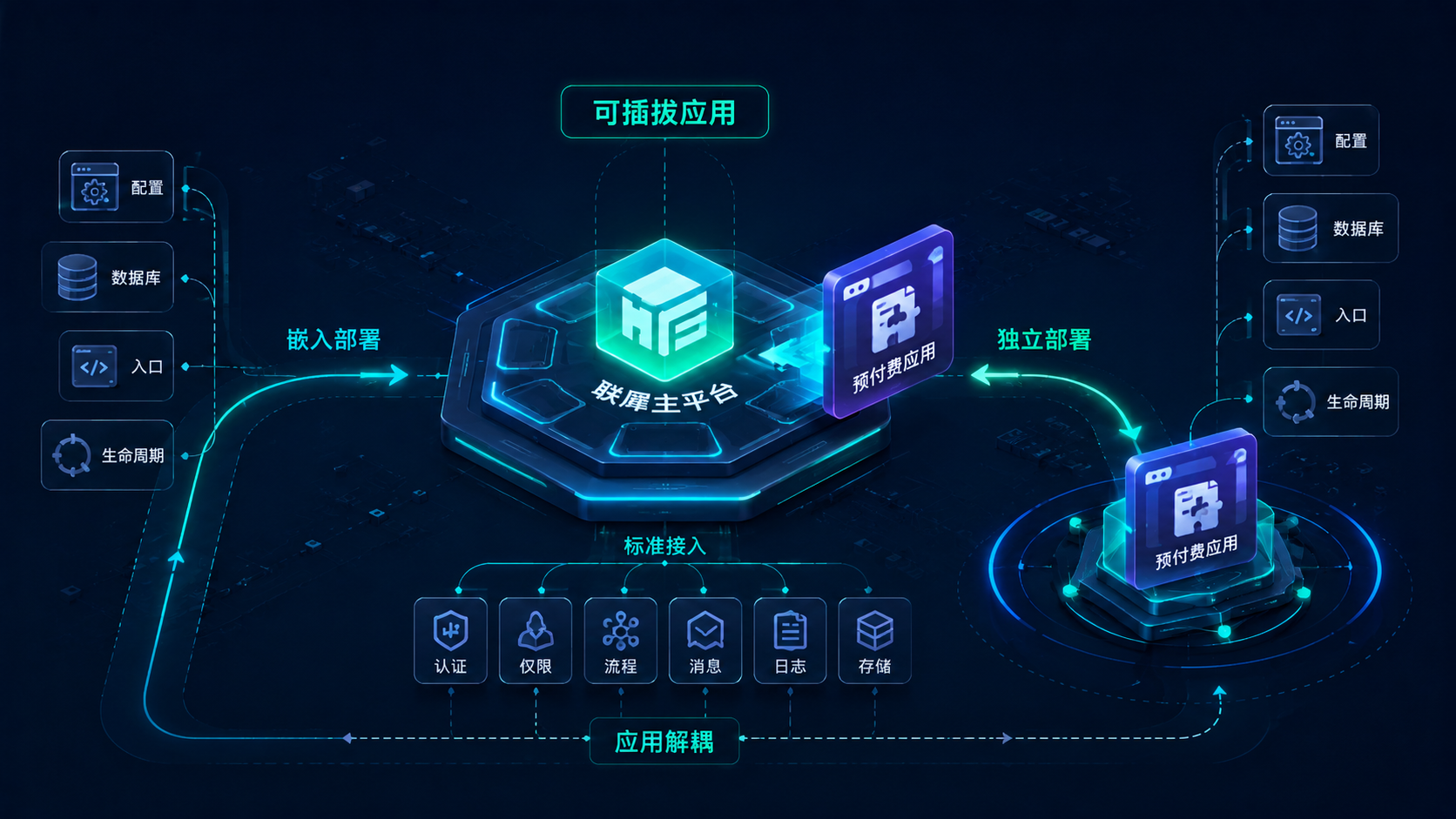
上面讲的是 core 和 things 这两个主模块如何在 AllInOne 和微服务之间切换。但联犀的架构还有一个更灵活的特性:新应用可以像插件一样接入,既可以嵌入 AllInOne 一体化部署,也可以独立运行、通过 gRPC 接入主平台。
以 prepaid(预付费应用)为例。它是一个独立的 Go module,有自己的 go.mod、自己的 .api 文件、自己的数据库模型和逻辑层,但它并不是从 core 或 things 里"长出来的",而是通过标准的 export 机制接入:
// backend/apps/prepaid/export/run.go
func Register() {
services.RegisterApisvr(func(server *rest.Server) error {
once.Do(func() {
var c config.Config
utils.ConfMustLoad("etc/prepaid.yaml", &c)
relationDB.Migrate(c.Database) // 独立的数据库迁移
ctx := svc.NewServiceContext(c)
handler.RegisterHandlers(server, ctx) // 把 prepaid 的 HTTP 路由注册到同一个 server
startup.InitTimed(ctx)
})
return nil
})
}在 AllInOne 模式下,只需要在 main.go 里加一行注册:
// backend/cmd/allInOne/main.go
import prepaidExport "gitee.com/unitedrhino/prepaid/export"
func main() {
prepaidExport.Register() // 像插插件一样接入预付费应用
// ... 其他初始化
}prepaid 就获得了和 core、things 完全同等的地位——共享同一个 HTTP server、同一个认证中间件、同一套日志和监控体系。
但 prepaid 同时也有自己的独立入口:
// backend/apps/prepaid/prepaid.go
func main() {
var c config.Config
utils.ConfMustLoad("etc/prepaid.yaml", &c)
server := rest.MustNewServer(c.RestConf)
ctx := svc.NewServiceContext(c)
handler.RegisterHandlers(server, ctx)
server.Start()
}这意味着同一个 prepaid 应用,既可以:
- 嵌入 AllInOne:通过
export.Register()把路由注册到主进程,适合中小场景快速上线 - 独立部署:运行
go run prepaid.go,独占一个端口和进程,适合大租户隔离或独立扩缩容 - 后续拆分:如果预付费业务爆发,需要独立团队维护,它天然就是一个完整的服务,不需要从某个大模块里"剥离重构"
things-ee、lowcodesvr、viewsvr 也是同样的模式——它们都是可选插件,按需加载,不强依赖。go.work 里声明了这些模块,但 AllInOne 的 main.go 只注册真正需要的:
// backend/cmd/allInOne/svc_things.go
func Init() {
eeExport.Register() // things-ee 扩展(可选)
lowcodeExport.Init() // 低代码平台(可选)
viewExport.Init() // 可视化服务(可选)
}这种"插件化"架构带来的直接好处是:
- 新增业务不需要改造现有代码。做一个新应用,只需要新建一个独立 module,写好
export/run.go,在 AllInOne 里注册一行,就能上线。 - 应用之间天然解耦。prepaid 不会污染 core 的代码,lowcode 不会影响 things 的部署,每个应用有自己的数据库、自己的配置、自己的生命周期。
- 部署方式自由切换。同一个应用,小客户场景下嵌入 AllInOne,大客户场景下独立部署,甚至部分应用走微服务、部分应用走 AllInOne 的"混合部署"也能支持。
- gRPC 接入和直连调用并存。应用如果需要调用 core 或 things 的 RPC 能力,可以通过
grpc模式远程接入,也可以通过direct模式在 AllInOne 内直连,切换只需要改配置。
对联犀这种需要持续扩展业务域的平台来说,"插件化"是比"把所有功能都塞进一个仓库"更健康的演进方式。它既保留了 monorepo 的协同优势,又避免了"大仓库里所有东西互相耦合"的陷阱。
配套基础设施为什么同样重要
如果只是把服务边界和部署模式分开,系统仍然不够稳。
要让这种架构真正可长期演进,还必须把横切能力下沉到基础设施层。
例如 WebSocket,联犀不是把长连接能力分散到各个业务服务,而是统一收敛到 Hub、频道模型、自动订阅和鉴权分发这套体系里;Hook 扩展则把很多原本容易硬编码在主流程里的扩展点,沉成了可声明、可治理、可重试的正式机制;时序数据和设备链路也通过宿主收敛和统一查询思路被稳定下来。
这些基础设施的存在,使"融合式宿主"和"微服务模式"不只是部署策略,而是可被公共层支撑的工程能力。而当这些公共能力被稳定沉淀之后,AI 写代码时也更不容易在相似问题上反复发明新模式。
这种设计的边界是什么
当然,这并不意味着任何系统都应该照抄这种路线。
如果团队规模很大、服务边界已经高度稳定、每个子系统的扩缩容模式完全不同,那么更纯的微服务拆分可能更合适。反过来,如果业务极小且长期不会扩张,保持简单单体反而更经济。
联犀这套模式真正适合的是:既需要平台级抽象,又不希望过早承担纯微服务全部成本的系统;尤其是中台能力和设备链路能力同时存在、并且会持续演进的场景。
proto 拆分与 API 接口描述:降低 AI 认知负担的细节工程

联犀在工程实践中还做了两件看起来"小"、但对 AI 协作影响很大的事:一个服务里按业务域拆分多个 proto 文件,以及在 .api 定义中强制写接口描述文档。这两件事加在一起,显著降低了 AI 在理解和使用接口时的认知负担。
一个服务多个 proto:让 AI 按域理解,而不是面对巨型文件
在联犀的后端里,一个 RPC 服务通常对应多个 .proto 文件,而不是把所有接口塞进一个庞大的 proto 里。以 syssvr(系统服务)和 dmsvr(设备管理服务)为例:
backend/core/service/syssvr/proto/
├── app.proto
├── checkIn.proto
├── common.proto
├── department.proto
├── dict.proto
├── log.proto
├── mall.proto
├── notify.proto
├── ops.proto
├── platform.proto
├── role.proto
├── user.proto
└── ...
backend/things/service/dmsvr/proto/
├── area.proto
├── data.proto
├── deviceGroup.proto
├── deviceInteract.proto
├── deviceManage.proto
├── deviceMsg.proto
├── dmConfig.proto
├── dmShare.proto
├── otaManage.proto
├── productManage.proto
├── protocolManage.proto
├── scene.proto
└── ...这种拆分的直接好处是:当 AI 需要处理"字典相关逻辑"时,它只需要聚焦 dict.proto,而不需要在一个上千行的巨型 proto 里逐行寻找相关定义。proto 文件名本身就是最自然的导航线索。
对 AI 来说,这相当于把"服务 -> 业务域 -> 接口"的三层结构显性化到了文件系统层面。模型不需要靠猜测来判断"这个接口大概在哪里",而是可以直接通过文件名定位到正确的上下文。这在长上下文受限的场景下尤其有价值——AI 可以把有限的 token 花在真正相关的业务域上,而不是浪费在无关接口的扫描上。
API 里强制写接口描述:让 AI 在开发阶段就能写好,使用时就能自己找到
联犀在 .api 文件的接口定义中,通过 @doc 注解强制要求每个接口都写 summary 和 description。这不是为了生成给人看的 Swagger 文档,而是把它作为 AI 认知接口用途的第一手材料。
以 dict/detail.api 中的接口定义为例:
@doc(
summary: "添加字典详情"
description: "业务说明:为指定字典类型添加具体的字典项,包括展示值、字典值、排序、父子关系等。字典详情是字典分类下的具体选项,用于下拉选择、枚举映射等场景。"
authType: "platform"
isNeedAuth: "true"
group: "system/dict/detail"
resource: "system/dict/detail"
action: "create"
recordLogMode: "1"
)
@handler create
post /create (DictDetail) returns (WithID)
@doc(
summary: "获取字典详情列表"
description: "业务说明:查询指定字典类型下的字典项列表,支持按父节点、状态、标签、值等条件筛选。用于字典管理页面展示字典项,或前端下拉组件获取选项数据。"
authType: "platform"
group: "system/dict/detail"
resource: "system/dict/detail"
action: "view"
recordLogMode: "3"
)
@handler getList
post /get-list (DictDetailGetListReq) returns (DictDetailGetListResp)这里的 summary 告诉 AI"这个接口是干什么的",description 告诉 AI"在什么场景下用、参数是什么含义、返回结果怎么用"。当 AI 在开发阶段写代码时,它不需要去猜测"create 接口的业务语义是什么",因为描述已经写在了契约里;当 AI 在消费阶段调用接口时,它也不需要去翻源码理解用途,而是可以直接从 .api 文件中读到准确的业务说明。
这种"描述即契约"的做法,在 AI 协作流程中产生了两个直接价值:
第一,开发阶段:AI 写接口实现时,描述就是需求。
当 AI 看到 "为指定字典类型添加具体的字典项,包括展示值、字典值、排序、父子关系等" 时,它已经很清楚这个接口要处理什么数据、支持什么操作,不需要再靠猜测或反向从类型定义推断业务意图。描述越准确,AI 生成的逻辑越贴近真实需求。
第二,消费阶段:AI 调用接口时,描述就是导航。
当 AI 需要"给某个业务功能添加下拉选项"时,它可以通过 summary 和 description 快速定位到 dict/detail 下的相关接口,而不需要在几十个服务的几百个接口里盲目搜索。接口描述成了 AI 的"自解释索引",让它能自己找到需要的接口。
再来看一个物联网侧的例子。scene.api 中的接口描述:
@doc(
summary: "新增场景"
description: "创建场景联动规则,定义触发条件(if)、触发时机(when)和执行动作(then)。场景用于实现设备自动化控制逻辑,如温度超阈值自动开启空调。支持绑定区域和设置标签。"
authType: "admin"
group: "things/scene/info"
resource: "things/scene/info"
action: "create"
recordLogMode: "1"
)
@handler create
post /create (SceneInfo) returns (WithID)
@doc(
summary: "获取场景信息列表"
description: "查询场景列表,支持按名称、标签、区域、触发类型、状态等过滤。可按设备模式过滤触发或执行相关场景。返回场景基本信息,isOnlyCore=true时不返回详细规则。"
authType: "admin"
group: "things/scene/info"
resource: "things/scene/info"
action: "view"
recordLogMode: "1"
)
@handler getList
post /get-list (SceneInfoGetListReq) returns (SceneInfoGetListResp)这个案例和字典接口的区别在于:字典是中台通用能力,而场景联动是物联网核心业务。description 里不仅说明了"场景是什么",还直接给出了业务场景示例("温度超阈值自动开启空调"),并说明了过滤条件和返回规则的特殊行为(isOnlyCore=true 时不返回详细规则)。这意味着 AI 在调用 getList 时,已经知道什么时候该传 isOnlyCore,而不是在调试时才发现返回字段不完整。
联犀把这套要求固化进了定制版 goctl 的校验链路里:如果接口缺少 summary 或 description,代码生成阶段就会报错。这不是为了增加开发负担,而是为了让"接口自解释"成为项目的默认属性。当所有接口都有清晰描述时,AI 无论是写代码还是调代码,面对的都不再是"只有路径和参数名的裸接口",而是"带业务语义的可理解契约"。
多个 proto + 接口描述的组合效应
把"一个服务多个 proto"和"API 强制接口描述"放在一起看,它们共同构成了一套"让 AI 逐层聚焦、逐层理解"的工程机制:
- 先定位服务:通过目录结构(
core/service/syssvr还是things/service/dmsvr)判断业务域 - 再定位 proto 文件:通过文件名(
dict.proto还是deviceManage.proto)判断具体子域 - 最后理解接口:通过
summary和description判断接口用途和使用场景
每一步都不需要 AI 去猜,每一步都有明确的线索。这正是在大规模代码库中,让 AI 保持高效和准确的关键。
为什么这套组合特别适合 SaaS + IoT
SaaS + IoT 最大的特点,是系统一半在做中台,一半在做设备链路。
这两边既有差异,又有大量共享基础设施,例如:
- 权限上下文
- API 风格
- 事件总线
- 配置管理
- 通知与日志
- 共享客户端
如果没有一套统一的代码生成与工程结构约束,这种跨域系统很容易越长越散。
go-zero 在联犀里的价值,就是帮我们把"跨域协同"控制在同一语言、同一工程骨架、同一生成链路之下,而不是让每个子域自由长成不同框架风格。
与此同时,联犀的 SaaS + IoT + AI 三线并行,也意味着系统需要在不同阶段承受不同的部署压力。中台能力可能更适合独立服务化演进,而设备链路能力可能在早期更适合融合宿主以降低成本。go-zero + goctl + monorepo + 融合式宿主的组合,让联犀不需要为"今天怎么部署"和"明天怎么拆分"做两套实现,而是同一套代码、同一套接口、同一套生成链路,按需选择运行方式。
这套选择的代价是什么
当然,选择 go-zero 并配合定制版 goctl,也不是没有代价。
最大的代价有两个。
一是需要维护自己的模板和约束
一旦走上模板控制路线,就意味着不能完全依赖上游默认行为。团队需要对生成结果负责,也要理解哪些是框架默认,哪些是项目定制。
二是要求团队尊重"定义先行"
goctl 的优势建立在接口定义足够清晰的前提上。
如果团队习惯先随手写代码,再回头补契约,这套方式反而会觉得束手束脚。
但对联犀来说,这两项代价是值得的。因为平台越大,结构一致性越值钱。
总结
联犀选择 go-zero,并不是因为它只是"一个不错的 Go 微服务框架",而是因为它和 goctl、模板控制、monorepo/workspace 结构以及融合式宿主架构组合起来之后,刚好满足了平台型项目最需要的几件事:
- 用定义驱动结构
- 用代码生成稳定骨架
- 用模板控制固化项目约束
- 用 monorepo 组织跨域共享与协同演进
- 用融合式宿主兼顾早期成本与后期演进
- 用多个 proto 和接口描述降低 AI 的认知负担
而到了 AI 深度参与研发的阶段,这套选择的价值反而更明显了:
- monorepo 让 AI 能沿着模块边界逐层聚焦,减少无效上下文
- goctl 让大量样板结构天然规范,减少 AI 自由发挥带来的漂移
- 模板控制让项目约束直接体现在骨架里,而不是每次都靠 prompt 重讲一遍
- 生成与校验链路把很多错误前移到"还没进入业务代码"之前
- 一个服务多个 proto 让 AI 可以按文件名快速定位业务域,不用在巨型文件里盲目扫描
- API 接口描述让 AI 在开发和消费阶段都能"自己理解接口",而不是靠猜测或反向推导
所以如果把问题放到今天更真实的语境里,它不只是"如何长期维护一个 SaaS + IoT 平台级代码库",也是"如何让人和 AI 都能在同一套代码库里持续稳定地产出规范代码"。在这个意义上,go-zero + goctl + 模板控制 + monorepo + 融合式宿主 + 接口自描述的组合,已经不只是开发效率工具链,而是一套面向 AI 协同开发时代的工程组织方式。
更新日志
2026/6/1 18:12
查看所有更新日志
8365c-于003fd-于d1cab-于f3628-于e2326-于ea53f-于fd6dd-于3a4f0-于43ef3-于
