联犀知识库的实现:从工具化到检索链路治理
知识库是什么,以及为什么它不能和 skills 互相替代
很多人会把知识库和 skills 混为一谈,觉得既然 AI 已经能调用工具了,直接把文档内容做成技能不就行了吗?实际上两者解决的是完全不同的问题。
知识库是什么
知识库本质上是一个"文档检索系统"。团队把产品文档、协议说明、操作手册、FAQ 等资料上传到平台,系统会对这些文档做切片、向量化、索引化,后续用户提问时,系统能从这些资料中找到最相关的段落作为回答依据。
它不是让 AI"记住"这些文档——大模型本身并不存储知识库内容——而是让 AI 在回答时能够"查资料"。就像医生看病时会查阅病历和医学文献一样,知识库给 AI 提供的是有据可查的回答基础。
为什么有了 skills 还需要知识库
联犀的 AI 体系里,skills(技能)是指 AI 可以调用的外部工具接口,比如查询设备列表、读取物模型属性、执行远程控制等。skills 解决的是"怎么做"的问题——让 AI 具备操作平台的能力。
但 skills 有一个天然限制:它只能返回结构化数据。一个设备当前温度是多少、某个产品支持哪些协议,这些用 skills 查很合适。但如果用户问的是"物模型属性上报的格式应该怎么填写",这个问题没有现成接口可以直接返回答案,答案藏在一篇文档的某个章节里。
这就是知识库的价值所在:它解决的是"知不知道"的问题。skills 负责行动,知识库负责背书。没有知识库,AI 遇到文档型问题只能靠训练时的"记忆"来回答,既容易过时,也无法覆盖团队私有的、未公开的资料。没有 skills,AI 知道答案却执行不了操作。两者互补,缺一不可。
而且,知识库的内容是团队自己维护的——文档更新、增补、修订,团队可以自主控制 AI 掌握的知识边界,而不必等待模型重新训练。
联犀知识库的实现路径
联犀在接入知识库的第一版里,采用的是最直接的做法:用户一提问,系统先做一轮向量检索,把命中的内容尽可能多地塞进 prompt,再交给模型回答。这个方案短期非常好理解,团队很快就跑通了原型,但只要知识库规模变大、问题复杂度上升,延迟就会迅速失控,而且"明明文档里有,却搜不到"的情况也越来越多。
这篇文章不是泛泛讨论"知识库延迟怎么压",而是从头梳理联犀知识库的实现路径:第一版怎么做的,遇到了哪些问题,为什么把检索改成工具,后来又怎么一步步补上准确度治理。问题的根源并不只是向量库快不快,也不只是模型推理速度够不够,而是检索链路本身缺少分层和治理。联犀在知识库能力上的改造,重点不是换一个搜索接口,而是把"固定前置检索"升级成"知识搜索工具化",再在这个基础上补齐查询重写、混合搜索和精排,让检索本身变成可调度、可观察、可分层执行的一套能力。
联犀第一版是怎么做的,以及遇到了什么问题
联犀第一版的做法,是把知识库当成一个自动附加的上下文包。用户提问后,系统不区分复杂度,也不区分查询意图,先做一轮大而全的向量搜索,再把大段命中文本直接拼进模型输入。这个方案在小知识库里(几十篇文档)跑得很快,实现也简单,团队很快就上线了。
但问题很快暴露出来。第一,检索层和推理层没有边界。检索返回多少,模型就被迫读多少,最终延迟随着上下文长度一起上涨。第二,系统缺少中间决策点。即便首轮检索已经够回答问题,它还是会把额外内容一股脑带给模型;即便首轮证据明显不够,它也没有一个稳定机制继续"追问知识库"。
当知识库规模超过 200 个文档之后,体感问题开始变得明显:简单问题也要等很久,复杂问题却依然答不准。更麻烦的是,有些问题明明文档里有答案,向量搜索就是搜不到——这不是模型的问题,而是检索链路本身太单薄,没有分层,也没有治理手段。联犀意识到,知识库不能只被当成"一次性预处理",它需要被设计成一套可治理的工具。
联犀怎么做工具化改造
联犀当前的思路,是把知识库搜索从固定前置步骤改造成运行时可调用的 backend tools。系统不再默认"先搜完再说",而是把知识能力拆成几个清晰的工具:
knowledge_searchknowledge_get_document_contentknowledge_get_chunk_relations
这三个工具的意义不是把一个搜索接口拆成三个名字,而是重新定义了检索链路的阶段。knowledge_search 负责拿到首轮候选证据;如果首轮只命中了标题、片段或局部描述,而问题本身需要更多上下文,就继续调用 knowledge_get_document_content 拉全文,或者调用 knowledge_get_chunk_relations 扩展关联切片。也就是说,知识检索不再只有"一次搜索"这一种动作,而是开始具备逐步收敛问题的能力。
这对延迟治理尤其重要。因为真正耗时的,往往不是"做一次轻量搜索",而是"把还没确认必要的内容也都塞给模型"。知识搜索被工具化之后,系统终于可以把"首轮搜索""证据扩展""二次搜索"拆成不同成本层级,而不是让所有问题一上来都走最重路径。
结构化搜索结果:延迟治理的关键
联犀在优化延迟时走过一个弯路:第一反应也是减少搜索次数,觉得"只搜一次"一定更快。但实际测试后发现,真正值得优化的不是次数本身,而是上下文负载。一次轻量搜索加一次按需扩展,往往比"一次搜索直接带一大堆上下文"更快,也更稳。因为模型的推理成本并不是线性跟着问题复杂度增长,而是对输入规模非常敏感。
联犀的解决方案是把搜索结果结构化返回,而不是直接把所有命中内容拼成 prompt。首轮搜索结果会区分:
- 原问题
- 改写后的查询
- 命中文档
- 直接证据切片
- 关联补充证据
- 置信区间
这种结构的意义在于,聊天编排层终于知道"现在手里到底拿到了什么"。它可以根据证据是否充分决定下一步,而不是只会把内容继续往模型里塞。对于简单问题,首轮搜索结果可能已经足够回答;对于复杂问题,系统则可以基于已有证据决定是扩全文、查关系,还是重新搜索。延迟因此不再完全由知识库大小决定,而更多取决于问题到底需要多少层信息。
为什么走 tool-first 路径
把知识搜索改成工具之后,联犀发现模型的工作方式更接近推理,而不是接近背诵。在传统前置检索模式下,模型拿到的是一个已经混合好的大 prompt,它并不知道哪些是核心证据,哪些只是上下文噪音。而工具化之后,模型会显式看到:现在可以先搜、再看全文、再查关联。它不再被动接收一包资料,而是被引导按步骤获取知识。
联犀没有把复杂问题的处理过程硬编码成固定多轮编排,而是通过工具和系统提示的组合,让 runtime 优先走 tool-first 路径。实际运行中,很多复杂问题不是"搜一次就能答",而是需要先定位主题,再确认具体章节,最后补齐上下文。工具化设计让这种多步取证变得自然,而不是靠人工写死流程。当某个问题类型明显需要额外证据时,团队可以继续扩工具和提示,而不必推翻整个聊天主链。
联犀怎么做准确度治理:三阶段检索升级
工具化上线之后,联犀解决了"可调度"问题,但"能调度"不等于"搜得准"。知识库规模扩大后,团队很快发现新的问题:简单问题虽然变快了,但某些明确相关的问题却搜不到对应文档。比如查询"设备物模型属性上报应该怎么填写"时,明明知识库中有 14.物模型协议/README.md,向量搜索就是无法命中。
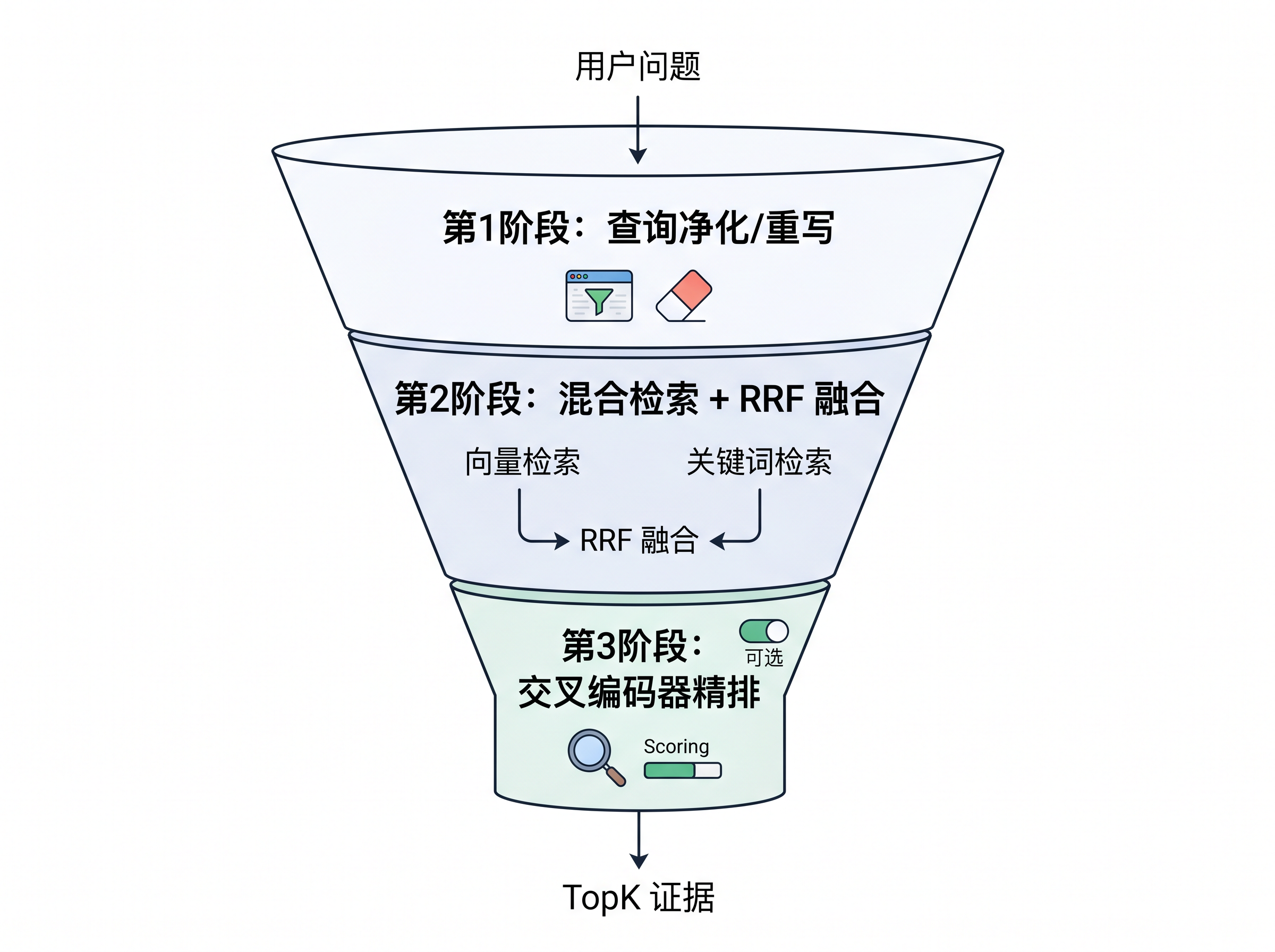
这说明检索链路不仅需要治理延迟,还需要专门治理准确度。联犀在工具化基础上,把检索链路升级为三阶段架构:查询重写净化、混合搜索与 RRF 融合、Cross-Encoder 精排。每一阶段都可以独立开关和调优,不再依赖单一搜索接口的"黑盒"行为。
Stage 1:查询重写净化
早期实现中,查询重写会把查询拆成大量 n-gram(如"备物"、"物模"),再把这些不成词的片段也送入 embedding 模型。这导致查询向量方向被污染——原始语义"设备物模型属性上报"被稀释成一堆无意义片段,相关文档在向量空间中反而排不上号。
优化后的策略只做两件事:一是完全移除 n-gram 生成逻辑,保留原始查询的完整语义;二是做字符级停用词过滤(中文无空格分词,必须以字符级处理),去掉"怎么"、"应该"、"填写"等疑问后缀和无关动作词。查询"设备物模型属性上报应该怎么填写"被净化为"设备物模型属性上报",embedding 方向立刻清晰很多。
Stage 2:混合搜索与 RRF 融合
纯向量搜索有个天然短板:它擅长语义相似,但不擅长精确匹配专有名词和型号编号。为了互补,联犀引入了混合搜索——向量搜索和关键词搜索并行执行,然后用 Reciprocal Rank Fusion(RRF)融合两套结果。
融合公式本身很简单:对同一个文档或切片,分别给定向量排名和关键词排名,按 RRF 分数重新排序。但它的真正价值在于不再依赖此前硬编码的 guided search 规则。以前系统要靠人工维护的路径匹配规则来"boost"某些文档,规则越写越多,维护成本越来越高。混合搜索加 RRF 融合之后,同一文档如果在关键词侧排第一、向量侧排第十,融合后仍可能进入前列,不再需要人工写规则。
Stage 3:Cross-Encoder ONNX Rerank 精排
前两阶段解决的是"召回"问题——确保相关文档被纳入候选集。但候选集内部的最终排序,仍然依赖向量相似度或 RRF 分数,这两者都是"粗排"逻辑,对 query 和 document 的交叉语义理解有限。
第三阶段引入 Cross-Encoder 做精排:取 RRF 融合后的 TopK 的两倍作为候选,用 BAAI/bge-reranker-v2-m3 模型逐对计算 query-document 的相关性得分,再按精排分数取最终 TopK。Cross-Encoder 把查询和文档拼接后一次性编码,比双塔向量模型的语义对齐能力更强。
为了不增加不必要的部署负担,这一阶段被设计为可选配置(默认关闭)。ONNX Runtime 本地推理,模型文件约 2.2 GB,低内存环境可直接跳过精排阶段,前两阶段已能满足大部分场景。
动态召回量与自适应阈值
大知识库的一个常见问题是:固定召回量太小,导致相关文档根本没进入候选池。联犀把召回量 RecallK 与最终返回量 TopK 解耦,按知识库文档数动态计算:
RecallK = min(max(20, docCount/10), 50)394 个文档的知识库召回量为 39,500 个以上封顶 50。同时相似度阈值也随规模自适应缩放,避免小库噪音和大库漏召的两难问题。SQL 层增加 WHERE similarity > ? 过滤,低分 chunk 在数据库层就被剔除,不进入后续处理。
Round-robin 文档去重与批量查询
召回量扩大后,如果不做去重,高分文档可能垄断结果(多个切片来自同一文档)。联犀采用 Round-robin 交替选取:先按文档分组保留每文档最高分切片,再交替从不同文档中取结果,保证最终 TopK 覆盖尽可能多的不同文档。
此外,向量搜索后的 artifact/document 查询从 N+1 逐个查询改为两次批量查询(IDs IN (...)),延迟从数百毫秒降至百毫秒级。这意味着召回量增加的同时,响应时间反而缩短了。
检索链路的三阶段架构
如果把知识检索比作一个漏斗,那么现在的链路是:
- 查询重写净化 —— 确保进入漏斗的查询语义干净。
- 混合搜索 + RRF 融合 —— 向量与关键词双路召回,扩大漏斗入口。
- Cross-Encoder 精排(可选)—— 在漏斗出口做最后一轮质量筛选。
这三个阶段各自独立、可观测、可配置。调试工作台上可以看到每一阶段的中间结果:改写后的查询是什么、向量召回和关键词召回分别命中了谁、RRF 融合后的排序变化、精排前后的对比。这种分层设计让"为什么这次搜不到"变得可回答、可定位、可优化。
配套能力:回答兜底与调试工具
证据充分时的回答兜底
联犀在生产中发现一个容易被忽视的延迟来源:系统在拿到证据后,仍然要等待模型输出最终文本。如果模型在某些情况下没有稳定地产出结果,或者在复杂推理中耗时过长,用户体感依然很差。联犀在这部分做了一个很务实的兜底处理:如果 runtime 已经拿到了稳定知识证据,但最终文本为空,聊天逻辑会根据证据直接合成结构化回答,避免整轮请求白等之后只得到空回复。
这个兜底逻辑对体验非常关键。因为用户感知的延迟不是搜索服务的响应时间,而是"从提问到看到有用答案"的总时间。只要系统能在证据充分时更早给出可解释结果,它就已经在整体延迟上赢了一步。
搜索调试工作台与直调接口
知识库进入生产后,联犀的团队经常被追问两个问题:为什么这次搜不到,为什么这次搜到了但还这么慢。单靠日志远远不够回答这些问题。联犀在知识搜索工具化之后,配套上线了搜索调试工作台和直调接口,让团队可以按 Agent 或知识库直接观察:
- 原始查询是什么
- 改写后的查询是什么
- 命中了哪些文档
- 首轮证据和补充证据分别是什么
这类工具的价值不仅在于定位召回问题,也在于帮助团队看清"到底是哪一层在耗时"。如果首轮搜索很快,但全文扩展很重,优化方向就不一样;如果搜索本身不慢,但模型因为读了太多证据才慢,问题就出在上下文治理而不是向量检索。换句话说,调试能力不是附属物,而是知识库能否持续优化的前提。
相关开源仓库
这条链路在 .gits/ 下面也有两个开源补充仓库:.gits/cli 和 .gits/skills。
cli 仓库的定位,是把联犀平台能力整理成统一的 ur 命令行入口,并支持为 AI Agent 生成可消费的 Skill 文档。它说明一个方向:知识能力不应该只存在于聊天链路里,而应该逐步演进成可以被 CLI、调试工具和自动化环境统一调用的工具面。
skills 仓库则进一步把平台能力整理成一组可分发的 Skill 集合。虽然知识搜索工具本身主要仍然在 aisvr 内部,但 Skill 仓库代表的是同一种工程思想:把原本散落在业务接口中的能力,收敛成 AI 更容易理解和组合的工具入口。
总结
回顾联犀知识库的实现路径,真正的答案不是压缩某一个点的耗时,而是把整条检索链路从"一次性预处理"逐步升级为"可分层、可配置、可观测"的治理体系。联犀的做法可以概括成五件事:
- 不再把知识库固定为前置检索步骤,而是变成可调用工具。
- 不再只做一次搜索,而是允许按问题复杂度逐步扩展证据。
- 不再把所有命中内容直接喂给模型,而是先结构化整理结果。
- 不再把调试留给日志猜测,而是显式提供直调与工作台能力。
- 不再依赖单一向量搜索和硬编码规则,而是通过查询重写、混合搜索、可选精排三个阶段分层治理检索准确度。
从联犀的实践经验来看,知识库一旦进入 AI 主链路,延迟和准确度就不再只是向量库或模型本身的问题,而是整个系统有没有能力区分"该搜多少""该展开多少""什么时候可以收口""候选集是否足够多样""排序是否真正反映相关性"。把这些决策点设计出来,知识库能力才能从"接上了但很重"走向"真正可用、可控、可持续优化"。
更新日志
2026/5/29 00:42
查看所有更新日志
1680c-于3a4f0-于ec197-于
