 数据分析模块使用
数据分析模块使用
# 简述
在物联场景中存在大量的数据统计,大屏等场景,这时候如果每个都需要开发对应的接口,我们的工作量就会非常大,故开发了数据分析模块来提供超高拓展性的数据分析统计能力. 常规的数据统计大致有以下两种数据统计类型:
- 设备物模型数据
- 简单类型: 简单类型是指展示的报表数据直接来自于物模型定义,如设备上报的有电压,而报表正好需要展示最新的电压或电压的历史记录,这种方式直接通过调用获取设备物模型历史记录或最新记录即可实现
- 复杂类型: 复杂类型是指需要对数据进行一定的加工才符合展示或统计的需求.如统计一个区域的功耗,一个项目的功耗.这种方式是没办法直接从物模型来获取数据的,只能定时进行数据统计,整理到一个或多个表中,再通过专门的接口进行展现,这种展现的方式可以直接参考业务数据统计.
- 业务数据统计
- 单表统计: 单表统计比较简单,在联犀中推荐直接将统计的所有数据放入单表中,然后借助通用接口来进行灵活的数据展现.
- 多表统计: 多表统计一般是数据出自多个表,并且不适合定时统计到一个表中,这种方式在erp中会比较多,在联犀中推荐使用存储过程或视图的方式来进行实时的数据聚合,然后在联犀中配置为sql模式,将其简化成单表模式进行数据处理.
# 开发
目前我们只支持关系型数据库的统计,支持sql及表查询,我们推荐使用表查询的方式,如定时统计消息数量,则通过定时任务来获取对应的数据,然后存到统计表中.
新增一个统计我们需要先打开系统开发中的数据分析:
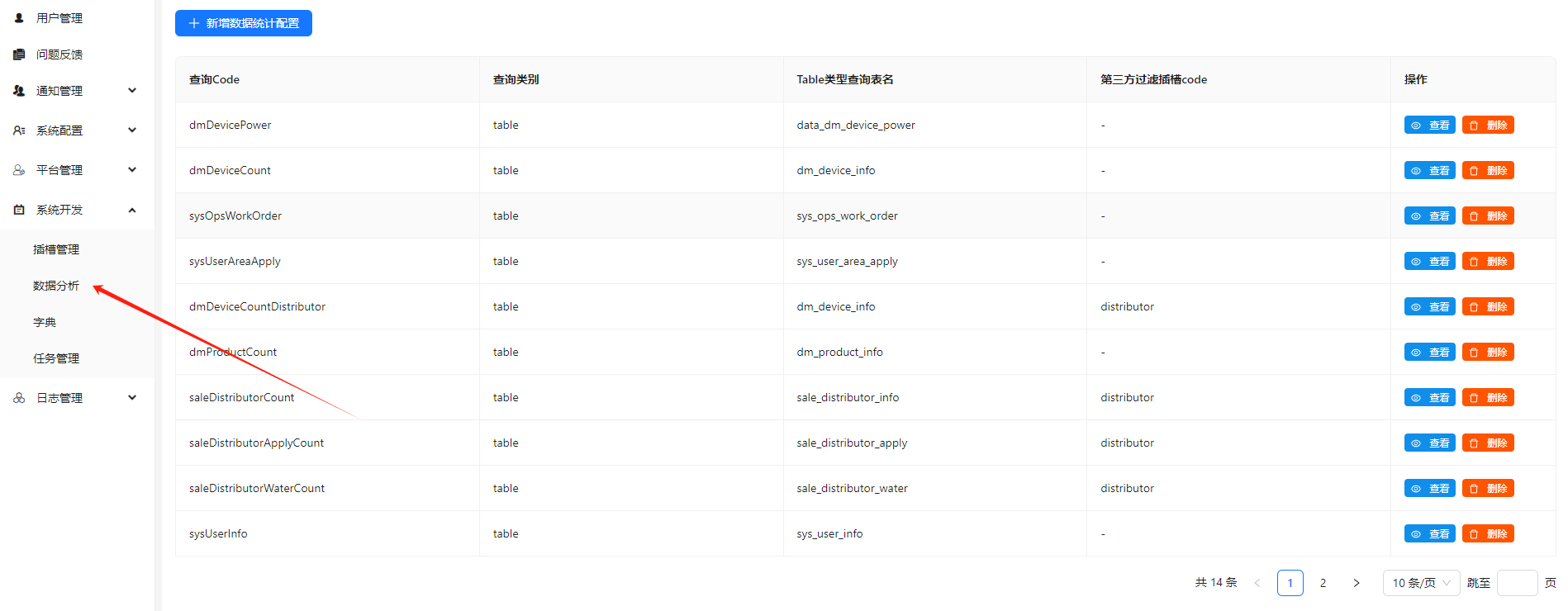
新建一个数据分析,参考设备消息统计的如下:
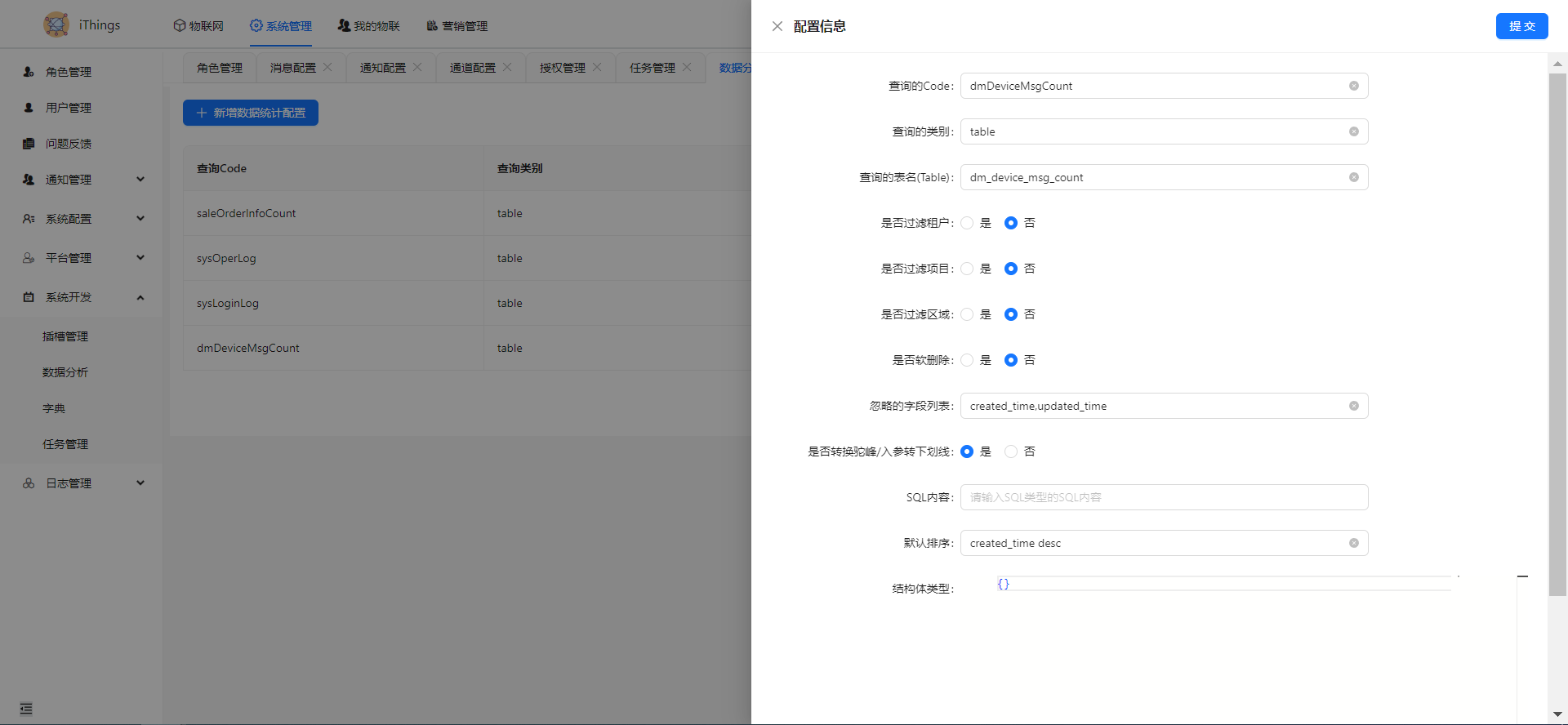
特殊字段说明:
| 字段 | 说明 |
|---|---|
| 是否软删除 | 联犀表结构支持软删除,如果是软删除类型,会默认加上已删除的过滤 |
| 是否转换驼峰/入参转下划线 | 如果为是,则会把接口传入的参数转换为下划线模式 |
| SQL内容 | 如果查询的类型是sql,这里需要填写查询的sql,一般是联表sql或func |
| 默认排序 | 在前端未传入排序字段的时候会默认按照这个参数进行排序 |
| 结构体类型 | 当需要一些定制查询参数时,可以进行配置,参考下面的图片 |
结构体类型示例:
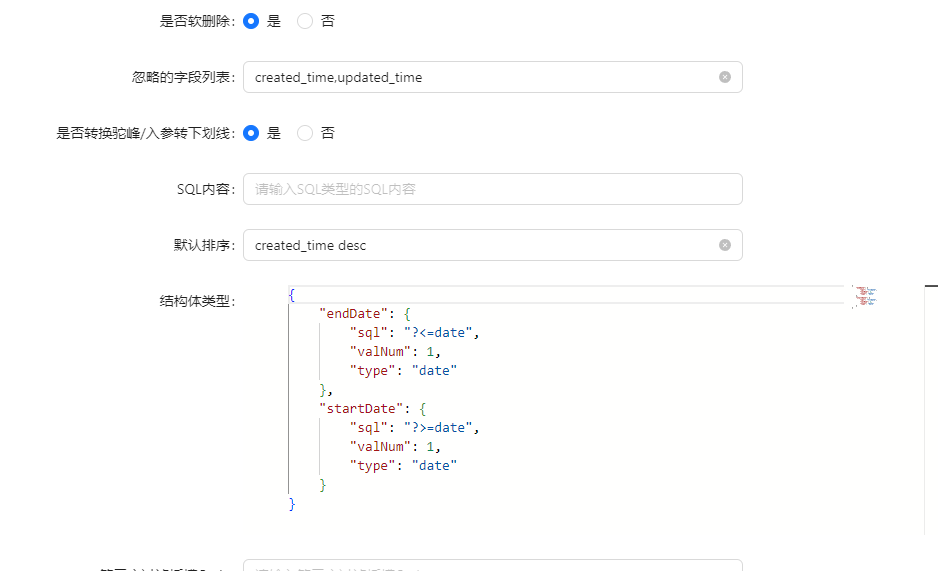
# 前端调用
数据配置好后,前端有两个接口可以进行调用,一个批量,一个单个,建议一个页面只调用一次,这样速度是最快的
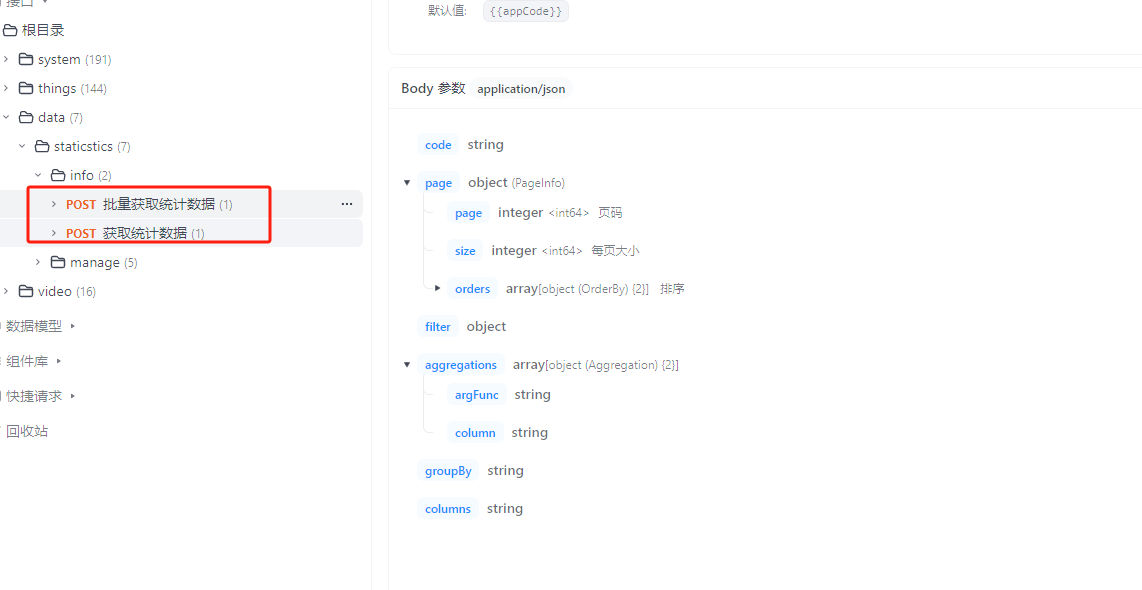
# 调用参数示例
- 设备发送消息统计
{
"code": "dmDeviceMsgCount",
"aggregations": [
{
"argFunc": "sum",
"column": "num"
}
],
"groupBy": "hourFmt:date",
"columns": "hourFmt:date",
"filter": {
"dayFmt:date:>=": "2024-09-04",
"type": "publish"
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- 设备在线状态统计
{
"code": "dmDeviceCount",
"argFunc": "count",
"aggregations": [
{
"argFunc": "count",
"column": "total"
}
],
"groupBy": "isOnline",
"columns": "isOnline"
}
1
2
3
4
5
6
7
8
9
10
11
12
2
3
4
5
6
7
8
9
10
11
12
- 各个应用的登录曲线
{
"code": "sysLoginLog",
"argFunc": "count",
"aggregations": [
{
"argFunc": "count",
"column": "total"
}
],
"groupBy":"appCode,hourFmt:createdTime",
"columns":"appCode,hourFmt:createdTime",
"filter":{
"dayFmt:createdTime:>=":"2024-08-20"
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 参数说明
- 全部字段
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| code | String | 是 | 配置的数据分析模块的编码 |
| page | String | 否 | 分页 |
| page.page | Int | 否 | 分页,页码 |
| page.size | Int | 否 | 分页,一页的长度 |
| page.orders | String | 否 | 排序 |
| page.orders.field | String | 否 | 排序的字段,如果配置了转下划线可以传小驼峰格式 |
| page.orders.sort | Int | 否 | 排序的方式:1 从小到大、2 从大到小 |
| filter | Struct | 否 | 过滤参数,是key为过滤字段,value为过滤值的结构体,详情参考下面 |
| aggregations | Array.Struct | 否 | 聚合 |
| aggregations.argFunc | String | 否 | 聚合的函数: 如count,sum,具体也可以参考数据库的聚合函数 |
| aggregations.column | String | 否 | 聚合的字段 |
| groupBy | String | 否 | 统计的分组字段,可以填写多个字段,用逗号分隔 |
| columns | String | 否 | 返回的字段列表,可以填写多个字段,用逗号分隔 |
- 字段特殊格式化 在groupBy,columns和filter key中的格式化方法 可以使用格式化来进行数据的提前处理再比较或展示,使用方式为 格式化方法(可选):字段名
支持的参数:
| 参数 | 说明 |
|---|---|
| dayFmt | 格式化为天 |
| hourFmt | 格式化为小时 |
| mouthFmt | 格式化为月 |
| yearFmt | 格式化为年 |
可以参考以下参数:
{
"code": "sysLoginLog",
"argFunc": "count",
"aggregations": [
{
"argFunc": "count",
"column": "total"
}
],
"groupBy":"appCode,hourFmt:createdTime",
"columns":"appCode,hourFmt:createdTime",
"filter":{
"dayFmt:createdTime:>=":"2024-08-20"
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- filter
优先匹配配置了过滤参数的特殊过滤,如果不匹配,会走以下逻辑
key为过滤的字段,默认字符串类型会用like进行匹配,数字类型用=
如果不能满足或需要一定的处理再进行匹配
- 如获取当天的数据,则可以使用:
"dayFmt:createdTime":"2024-08-20"则可以过滤创建时间为2024-08-20的数据 - 如果是需要获取 8月20号之后的则可以修改为
"dayFmt:createdTime:>=":"2024-08-20"
key格式: 格式化方法(可选):字段名:比较方法(可选)
比较方法在数据库定义的比较类型(=,>=,> ...)之外有以下几个特殊的:
- 如获取当天的数据,则可以使用:
| 参数 | 说明 |
|---|---|
| jsonEq | jsonEq的格式为xxx.xxx:jsonEq 是专门比较json类型的字段 |
| in | 和数据库中的in相同,value以逗号分隔 |
| subChildren | 树型的节点如果需要同时获取其子节点可以用该过滤方式,底层使用 like 'xxx%' 来进行匹配,具体表结构定义可以查看区域的表结构定义 |
上次更新: 2024/11/12, 13:18:12
