 tdengine结合物联网平台落地
tdengine结合物联网平台落地
# 简述
在当下的物联网行业中,TDengine已经成为国内占有率最高的开源时序数据库,而在开源物联网平台中,也成为了刚需组件,接下来将会分几个模块来讨论下联犀物联网平台是如何结合TDengine,并且将TDengine的拓展性提升到一个高点。
# 物模型如何结合TDengine
# 物模型介绍
现实世界是由真实存在的物理设备所组成的,我们可以将这些设备称之为“物”。物联网的目的则是能够将现实世界中的万“物”通过网络连接在一起,并将其数字化成云端的服务或者资源,通过整合各类服务资源实现智能化。因此,在物联网所构建的数字世界里,我们首先需要对“物”有一个清晰、统一的定义,用于描述“物”具体能做什么,能够提供什么样的服务和资源。ICA联盟从产品层面对“物”进行了功能建模,定义出统一的“物的抽象模型”以及“物的描述语言(TSL,Things Specification Language)”
物的抽象模型是对“设备是什么”、“设备能做什么”的一种描述,包括有:物的状态、物的档案信息、物的功能定义。
 我们需要重点关注的是物模型中的属性(property),属性详细解释如下:
我们需要重点关注的是物模型中的属性(property),属性详细解释如下:
智能电灯的状态具有二元性:它要么处于开启状态,要么处于关闭状态。用户可以通过控制操作轻松地在这两种状态之间切换。此外,某些智能电灯还支持高级功能,允许用户根据个人喜好或需求调整亮度、颜色和色温等参数。
智能设备的属性具备读写能力,这意味着应用程序不仅可以读取这些属性以获取设备当前的状态信息,还可以修改它们以改变设备的行为。例如,在环境监测设备中,应用程序可以读取并显示当前的温度和湿度,同时也能够根据需要调整这些参数,以适应不同的环境条件。
# 物模型如何结合TDengine
# 物模型超级表与产品的关系
在联犀中有公共物模型和产品物模型两种,公共物模型是多个产品共同定义的物模型.
当我们定义一个物模型时会发生以下操作:
- 产品物模型: 每一类特定产品设备使用一个超级表。
- 通用物模型: 只创建一个超级表,后续的各个产品可以按需引入这个物模型,产品下的设备也就可以直接使用这个超级表。
TDengine 支持灵活的数据模型设计,既可以采用多列模型,也可以采用单列模型。多列模型即定义为结构体类型,将多个字段存储在同一张超级表中,这种模型在写入和存储效率上通常更优。然而,在某些情况下,例如数据采集点的采集量种类经常变化,单列模型可能更为合适,因为它简化了应用程序的设计和管理,允许独立地管理和扩展每个物理量的超级表。
综上所述,TDengine 提供了灵活的数据模型选项,用户可以根据实际需求和场景选择最适合的模型,无论是窄表设计还是多列与单列模型的选择,都是为了优化性能和管理复杂性。
# 物模型和表对应关系
超级表的定义分为三种:
- 普通类型: 根据物模型的数据类型,映射单列模式的超级表.
物模型定义示例: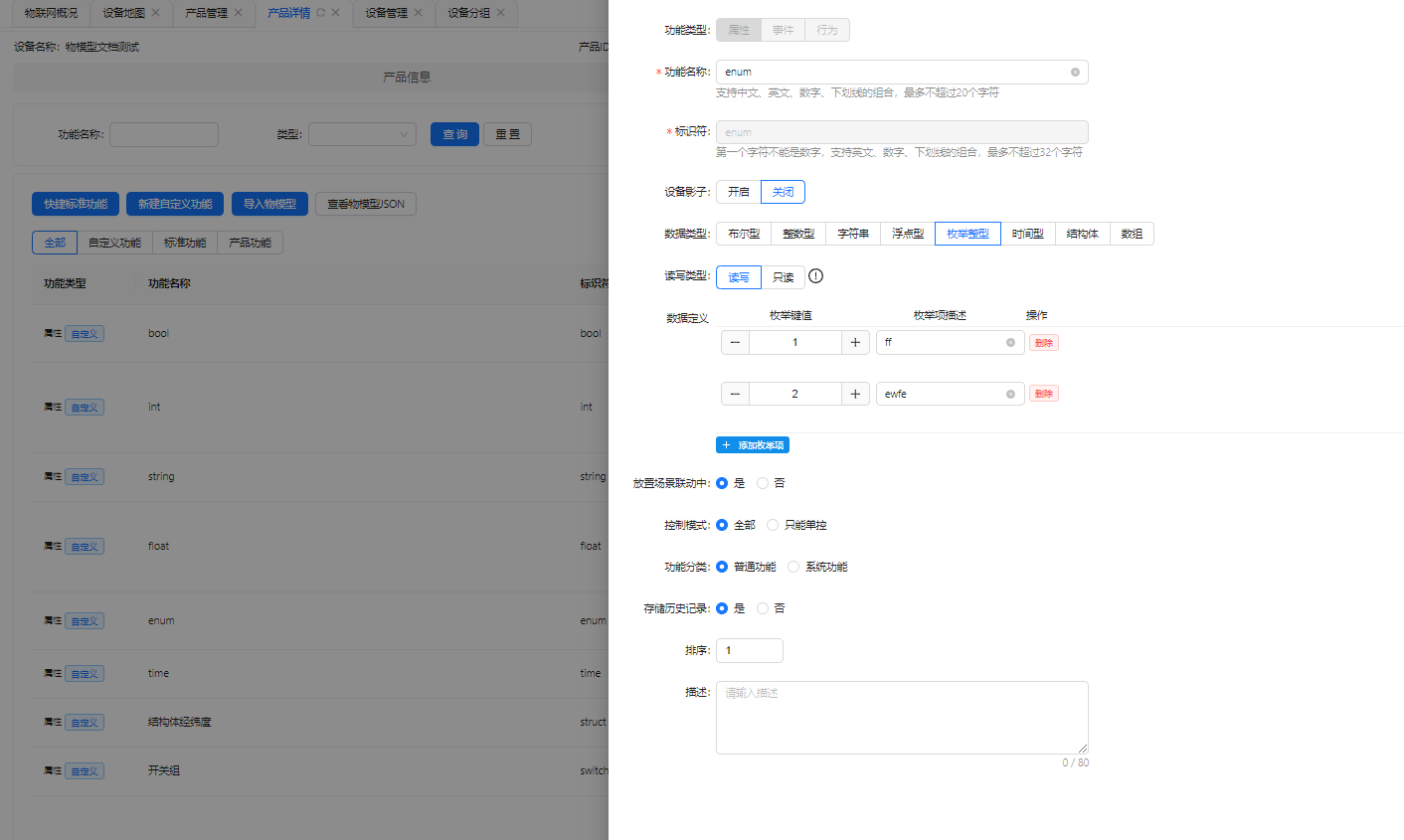
示例sql如下:
CREATE STABLE IF NOT EXISTS `model_custom_property_00b_int` (`ts` timestamp,`param` BIGINT)
TAGS (`product_id` BINARY(50),`device_name` BINARY(50),`property_type` BINARY(50));
2
参数说明:
| 字段 | 类型 | 说明 |
|---|---|---|
| model_custom_property_00b_int | 超级表名 | 组成为 模型_物模型的类型(自定义物模型,通用物模型)_属性_产品ID_属性名称 |
| ts | 表字段 | 时间戳,主键 |
| param | 参数 | 设备数据就存在这里字段中 |
| product_id | 产品id | 设备所属的产品ID |
| device_name | 设备名 | 同时也叫sn |
| property_type | 属性的类型 | 在获取数据的时候方便序列化数据 |
param 物模型和TDengine的表的定义对照如下:
| 物模型类型 | TDengine表结构 | 说明 |
|---|---|---|
| int | BIGINT | 整形 |
| float | DOUBLE | 浮点型 |
| enum | SMALLINT | 枚举类型 |
| timestamp | TIMESTAMP | 时间戳类型 |
| bool | BOOL | bool类型 |
| string | BINARY | 字符串类型 |
下面是完整的建表语句:
CREATE STABLE IF NOT EXISTS `model_custom_property_00b_int` (`ts` timestamp,`param` BIGINT) TAGS (`product_id` BINARY(50),`device_name` BINARY(50),`property_type` BINARY(50));
CREATE STABLE IF NOT EXISTS `model_custom_property_00b_float` (`ts` timestamp,`param` DOUBLE) TAGS (`product_id` BINARY(50),`device_name` BINARY(50),`property_type` BINARY(50));
CREATE STABLE IF NOT EXISTS `model_custom_property_00b_enum` (`ts` timestamp,`param` SMALLINT) TAGS (`product_id` BINARY(50),`device_name` BINARY(50),`property_type` BINARY(50));
CREATE STABLE IF NOT EXISTS `model_custom_property_00b_timestamp` (`ts` timestamp,`param` TIMESTAMP) TAGS (`product_id` BINARY(50),`device_name` BINARY(50),`property_type` BINARY(50));
CREATE STABLE IF NOT EXISTS `model_custom_property_00b_bool` (`ts` timestamp,`param` BOOL) TAGS (`product_id` BINARY(50),`device_name` BINARY(50),`property_type` BINARY(50));
CREATE STABLE IF NOT EXISTS `model_custom_property_00b_string` (`ts` timestamp,`param` BINARY(5000)) TAGS (`product_id` BINARY(50),`device_name` BINARY(50),`property_type` BINARY(50));
2
3
4
5
6
对应的每个设备创建的普通表如下:
CREATE TABLE IF NOT EXISTS `device_property_00b_device1_int` USING `model_custom_property_00b_int` TAGS('00b','device1','int');
CREATE TABLE IF NOT EXISTS `device_property_00b_device1_enum` USING `model_custom_property_00b_enum` TAGS('00b','device1','enum');
CREATE TABLE IF NOT EXISTS `device_property_00b_device1_bool` USING `model_custom_property_00b_bool` TAGS('00b','device1','bool');
CREATE TABLE IF NOT EXISTS `device_property_00b_device1_string` USING `model_custom_property_00b_string` TAGS('00b','device1','string');
CREATE TABLE IF NOT EXISTS `device_property_00b_device1_float` USING `model_custom_property_00b_float` TAGS('00b','device1','float');
CREATE TABLE IF NOT EXISTS `device_property_00b_device1_timestamp` USING `model_custom_property_00b_timestamp` TAGS('00b','device1','timestamp');
2
3
4
5
6
- 结构体类型: 拥有多个字段并将物模型的进行整体的抽象,映射多列模式的超级表。
物模型定义示例:
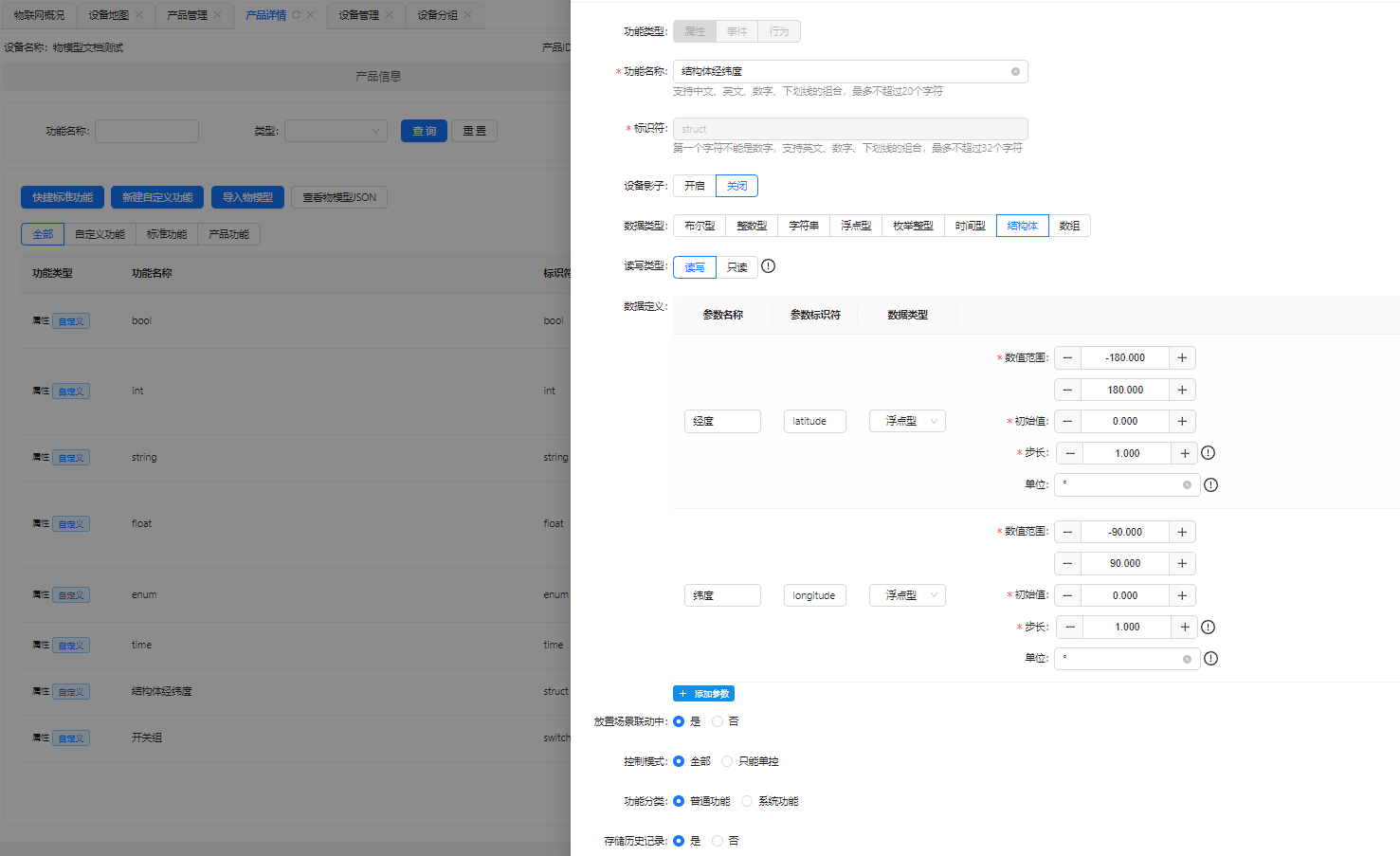 示例sql如下:
示例sql如下:
CREATE STABLE IF NOT EXISTS `model_custom_property_00b_struct` (`ts` timestamp, `latitude` DOUBLE,`longitude` DOUBLE) TAGS (`product_id` BINARY(50),`device_name` BINARY(50),`property_type` BINARY(50));
参数说明:
| 字段 | 类型 | 说明 |
|---|---|---|
| model_custom_property_00b_struct | 超级表名 | 组成为 模型_物模型的类型(自定义物模型,通用物模型)_属性_产品ID_属性名称 |
| ts | 表字段 | 时间戳,主键 |
| latitude | 参数 | 结构体类型中的经度 |
| longitude | 参数 | 结构体类型中的纬度 |
| product_id | 产品id | 设备所属的产品ID |
| device_name | 设备名 | 同时也叫sn |
| property_type | 属性的类型 | 在获取数据的时候方便序列化数据 |
对应的每个设备创建的普通表如下:
CREATE TABLE IF NOT EXISTS `device_property_00b_device1_struct` USING `model_custom_property_00b_struct` TAGS('00b','device1','struct');
- 数组类型: 数组类型比较特殊,常规物联网平台的数组是没法操作某一位的,如如果我想单独修改开关10的状态是不允许的,必须传[0,1,1,0,1,0,1,1,0,1]这样完整的数组才能控制,但是这其实是不符合真实的世界的,联犀将数组进行拓展支持下角标访问,如我需要更改开关10为开,则传递
"switch.10":1即可,我们来看下联犀是如何处理这样的数据结构.
物模型定义示例:
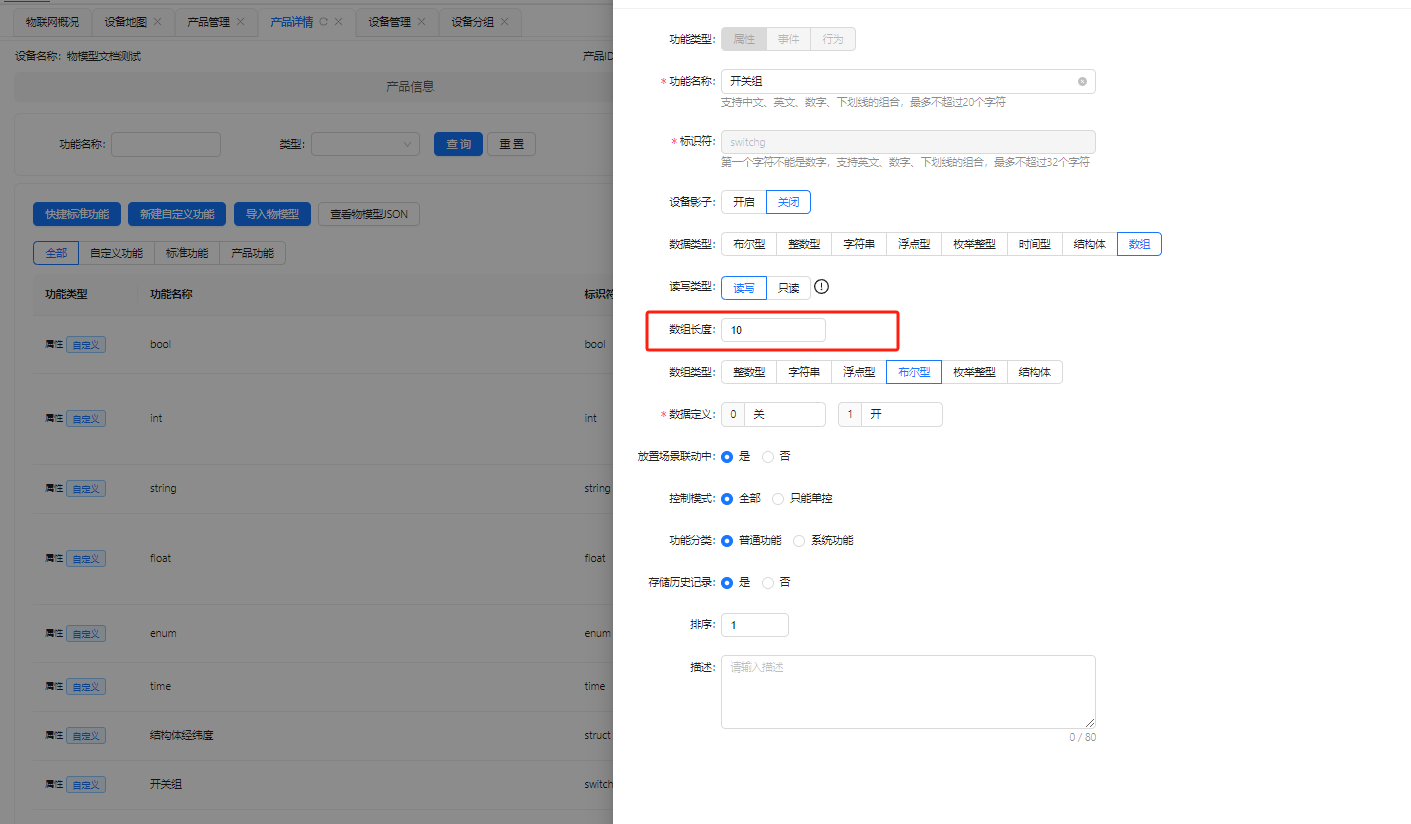
示例sql如下:
CREATE STABLE IF NOT EXISTS `model_custom_property_00b_switchg` (`ts` timestamp,`param` BOOL) TAGS (`product_id` BINARY(50),`device_name` BINARY(50),`_num` BIGINT,`property_type` BINARY(50));
2
参数说明:
| 字段 | 类型 | 说明 |
|---|---|---|
| model_custom_property_00b_switchg | 超级表名 | 组成为 模型_物模型的类型(自定义物模型,通用物模型)_属性_产品ID_属性名称 |
| ts | 表字段 | 时间戳,主键 |
| param | 参数 | 数组每一位的数据都存于此 |
| _num | 数组的下角标 | 表示数据属于哪一位 |
| product_id | 产品id | 设备所属的产品ID |
| device_name | 设备名 | 同时也叫sn |
| property_type | 属性的类型 | 在获取数据的时候方便序列化数据 |
可以看到和简单类型的定义是相似的,只是添加了个_num的字段来标识数组的下标,这样的好处是如果有1000个数组长度,这里只需要定义一个超级表,当然设备的普通表就需要定义1000个,但是因为是一个超级表来进行管理,所以管理起来也很方便.
我们来看下每个设备创建的普通表是啥样的:
CREATE TABLE IF NOT EXISTS `device_property_00b_device1_switchg_0` USING `model_custom_property_00b_switchg` TAGS('00b','device1',0,'bool');
CREATE TABLE IF NOT EXISTS `device_property_00b_device1_switchg_1` USING `model_custom_property_00b_switchg` TAGS('00b','device1',1,'bool');
CREATE TABLE IF NOT EXISTS `device_property_00b_device1_switchg_2` USING `model_custom_property_00b_switchg` TAGS('00b','device1',2,'bool');
CREATE TABLE IF NOT EXISTS `device_property_00b_device1_switchg_3` USING `model_custom_property_00b_switchg` TAGS('00b','device1',3,'bool');
CREATE TABLE IF NOT EXISTS `device_property_00b_device1_switchg_4` USING `model_custom_property_00b_switchg` TAGS('00b','device1',4,'bool');
CREATE TABLE IF NOT EXISTS `device_property_00b_device1_switchg_5` USING `model_custom_property_00b_switchg` TAGS('00b','device1',5,'bool');
CREATE TABLE IF NOT EXISTS `device_property_00b_device1_switchg_6` USING `model_custom_property_00b_switchg` TAGS('00b','device1',6,'bool');
CREATE TABLE IF NOT EXISTS `device_property_00b_device1_switchg_7` USING `model_custom_property_00b_switchg` TAGS('00b','device1',7,'bool');
CREATE TABLE IF NOT EXISTS `device_property_00b_device1_switchg_8` USING `model_custom_property_00b_switchg` TAGS('00b','device1',8,'bool');
CREATE TABLE IF NOT EXISTS `device_property_00b_device1_switchg_9` USING `model_custom_property_00b_switchg` TAGS('00b','device1',9,'bool');
2
3
4
5
6
7
8
9
10
# 如何发挥TDengine的性能
创建好表后,当设备上报自己的信息时,我们需要写入大量的数据,如在线120w个设备,每个设备10分钟上报一次,那么每秒就有2000个消息上来,每条消息需要入库一条调试日志和一条属性历史记录。我们做了大量的性能测试和优化,根据我们一开始的测试,突破 2000 qps是很难的一件事情,仔细了解了TDengine的体系架构之后,我们做了以下几点优化来进行优化。
- 从http更换为websocket: 在td3.x之后提供了websocket的模式,我们也顺势进行升级,经过测试性能有所提升,稳定性也有所提升,但是并发的情况下整个系统的资源消耗也还是会非常大.
- 将同步操作改为异步操作。
- 在TDengine中sql支持单个sql插入多条数据,甚至不是一个表也可以,这样可以大幅增加写入性能
官方语法:
INSERT INTO
tb_name
[USING stb_name [(tag1_name, ...)] TAGS (tag1_value, ...)]
[(field1_name, ...)]
VALUES (field1_value, ...) [(field1_value2, ...) ...] | FILE csv_file_path
[tb2_name
[USING stb_name [(tag1_name, ...)] TAGS (tag1_value, ...)]
[(field1_name, ...)]
VALUES (field1_value, ...) [(field1_value2, ...) ...] | FILE csv_file_path
...];
INSERT INTO tb_name [(field1_name, ...)] subquery
2
3
4
5
6
7
8
9
10
11
12
官方示例:
INSERT INTO d21001 USING meters TAGS ('California.SanFrancisco', 2) VALUES ('2021-07-13 14:06:34.630', 10.2, 219, 0.32) ('2021-07-13 14:06:35.779', 10.15, 217, 0.33)
d21002 USING meters (groupId) TAGS (2) VALUES ('2021-07-13 14:06:34.255', 10.15, 217, 0.33)
d21003 USING meters (groupId) TAGS (2) (ts, current, phase) VALUES ('2021-07-13 14:06:34.255', 10.27, 0.31);
2
3
联犀借助这个语法来进行异步操作,操作流程如下:
- 设备插入数据时先生成
d21003 USING meters (groupId) TAGS (2) (ts, current, phase) VALUES ('2021-07-13 14:06:34.255', 10.27, 0.31)这样格式的插入语句 - 将sql语句放入golang的 Channel中
- 多个异步入库协程会监听Channel,将数据取出,如果执行间隔超过1秒或sql数量达到上限,则会组成完整的sql插入到数据库中
由于设备上报数据整个流程都不涉及到磁盘操作,所以整体速度非常快,在未完全优化的情况下,经过我们的测试,单机情况下,8核16g,可以稳定跑7k的并发,并且保存毫秒级低延时及无任何一个错误!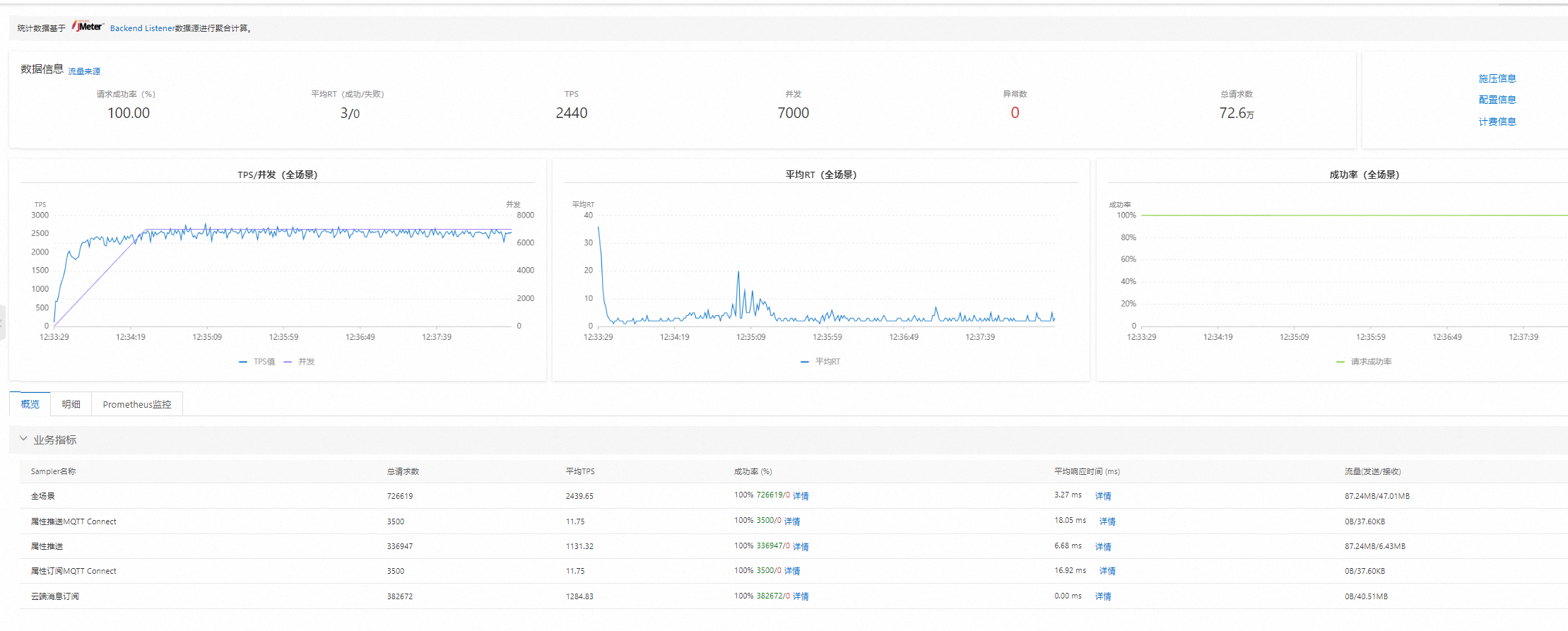
关键代码如下:
type Td struct {
*sql.DB
}
type ExecArgs struct {
Query string
Args []any
}
var (
td = Td{}
once = sync.Once{}
insertChan = make(chan ExecArgs, 1000)
)
const (
asyncExecMax = 200 //异步执行sql最大数量
asyncRunMax = 40
)
func NewTDengine(DataSource conf.TSDB) (TD *Td, err error) {
once.Do(func() {
if DataSource.Driver == "" {
DataSource.Driver = "taosWS"
}
td.DB, err = sql.Open(DataSource.Driver, DataSource.DSN)
if err != nil {
return
}
td.DB.SetMaxIdleConns(50)
td.DB.SetMaxOpenConns(50)
td.DB.SetConnMaxIdleTime(time.Hour)
td.DB.SetConnMaxLifetime(time.Hour)
_, err = td.Exec("create database if not exists ithings;")
if err != nil {
return
}
for i := 0; i < asyncRunMax; i++ {
utils.Go(context.Background(), func() {
td.asyncInsertRuntime()
})
}
})
if err != nil {
logx.Errorf("TDengine 初始化失败,err:%v", err)
}
return &td, err
}
func (t *Td) asyncInsertRuntime() {
r := rand.Intn(1000)
tick := time.Tick(time.Second/2 + time.Millisecond*time.Duration(r))
execCache := make([]ExecArgs, 0, asyncExecMax*2)
exec := func() {
if len(execCache) == 0 {
return
}
sql, args := t.genInsertSql(execCache...)
var err error
for i := 3; i > 0; i-- { //三次重试
_, err = t.Exec(sql, args...)
if err == nil {
break
}
}
if err != nil {
logx.Error(err)
}
execCache = execCache[0:0] //清空切片
}
for {
select {
case _ = <-tick:
exec()
case e := <-insertChan:
execCache = append(execCache, e)
if len(execCache) > asyncExecMax {
exec()
}
}
}
}
func (t *Td) AsyncInsert(query string, args ...any) {
insertChan <- ExecArgs{
Query: query,
Args: args,
}
}
func (t *Td) genInsertSql(eas ...ExecArgs) (query string, args []any) {
qs := make([]string, 0, len(eas))
as := make([]any, 0, len(eas))
for _, e := range eas {
qs = append(qs, e.Query)
as = append(as, e.Args...)
}
return fmt.Sprintf("insert into %s;", strings.Join(qs, " ")), as
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
# TDengine查询
数据插入到数据库中后,我们开始准备所涉及到数据的查询及展示,由于TDengine支持多种丰富的数据聚合方式,这让我们的数据分析十分方便。
# orm设计
灵活的查询方式缺不了orm的保障,而TDengine的官方库未提供orm框架,开源社区也没有TDengine的orm框架,因此 联犀 在著名的 orm框架squirrel(https://github.com/Masterminds/squirrel)上进行拓展,以支持TDengine的语法.
orm示例:
func (d *DeviceDataRepo) getPropertyArgFuncSelect(
ctx context.Context,
filter msgThing.FilterOpt) (sq.SelectBuilder, error) {
schemaModel, err := d.getSchemaModel(ctx, filter.ProductID)
if err != nil {
return sq.SelectBuilder{}, err
}
p, ok := schemaModel.Property[filter.DataID]
if !ok {
return sq.SelectBuilder{}, errors.Parameter.AddMsgf("dataID:%s not find", filter.DataID)
}
var (
sql sq.SelectBuilder
)
if p.Define.Type == schema.DataTypeStruct {
sql = sq.Select("FIRST(`ts`) AS ts", d.GetSpecsColumnWithArgFunc(p.Define.Specs, filter.ArgFunc))
} else {
sql = sq.Select("FIRST(`ts`) AS ts", fmt.Sprintf("%s(`param`) as param", filter.ArgFunc))
}
if filter.Interval != 0 {
sql = sql.Interval("?a", filter.Interval) //TDengine特有语法
}
if len(filter.Fill) > 0 {
sql = sql.Fill(filter.Fill)//TDengine特有语法
}
return sql, nil
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
仓库地址: gitee.com/i-Things/squirrel
# 灵活的查询接口
借助上述的orm底层实现,才可以实现灵活的查询接口,下面是我们的查询接口示例:
请求参数:
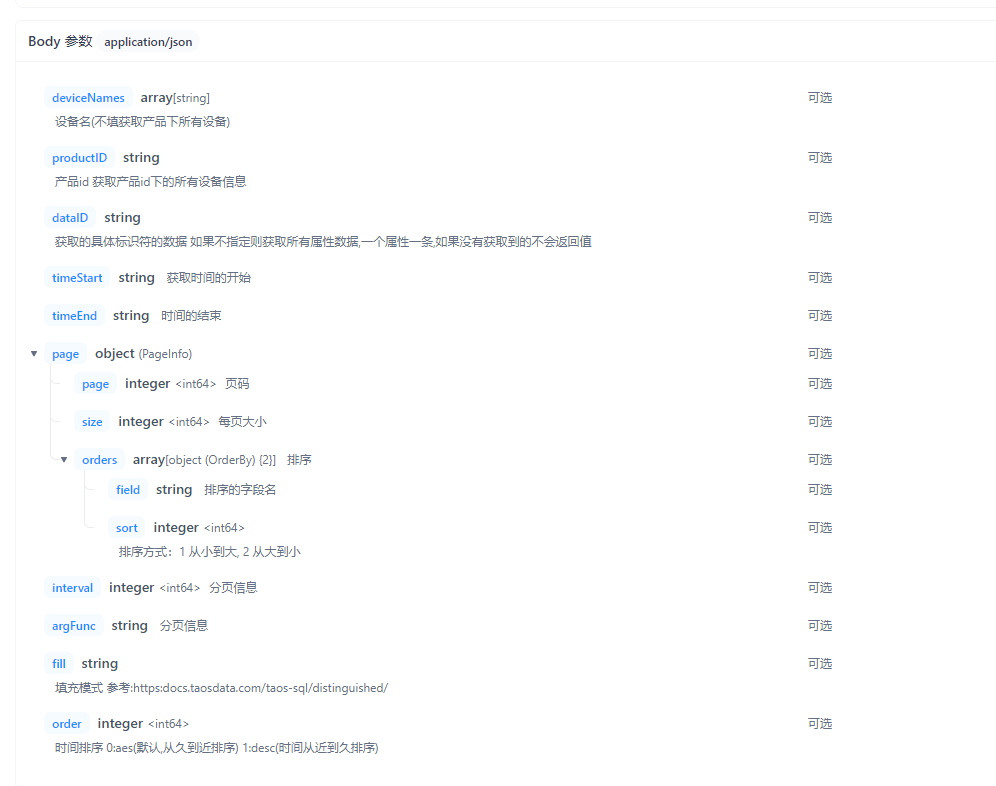
回复参数:
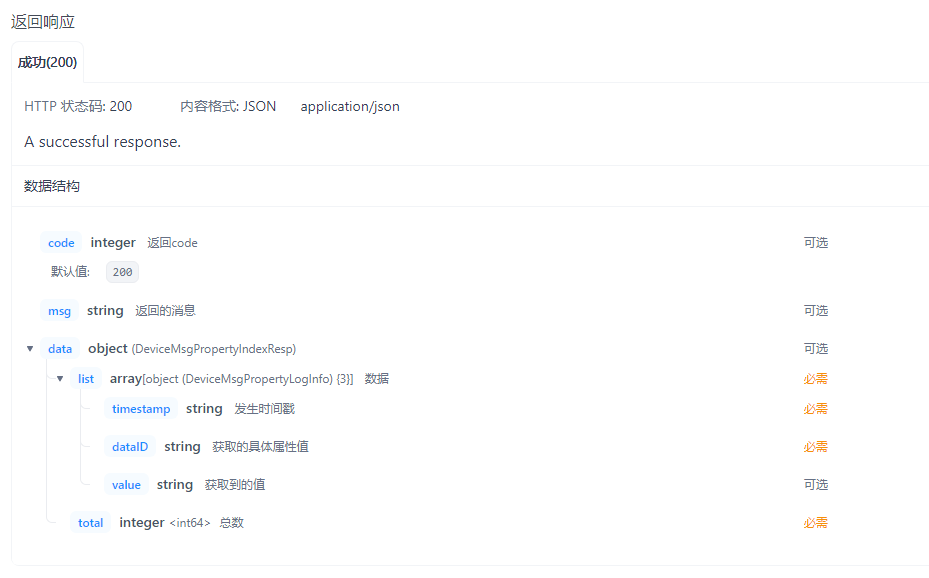
# TDengine链路追踪
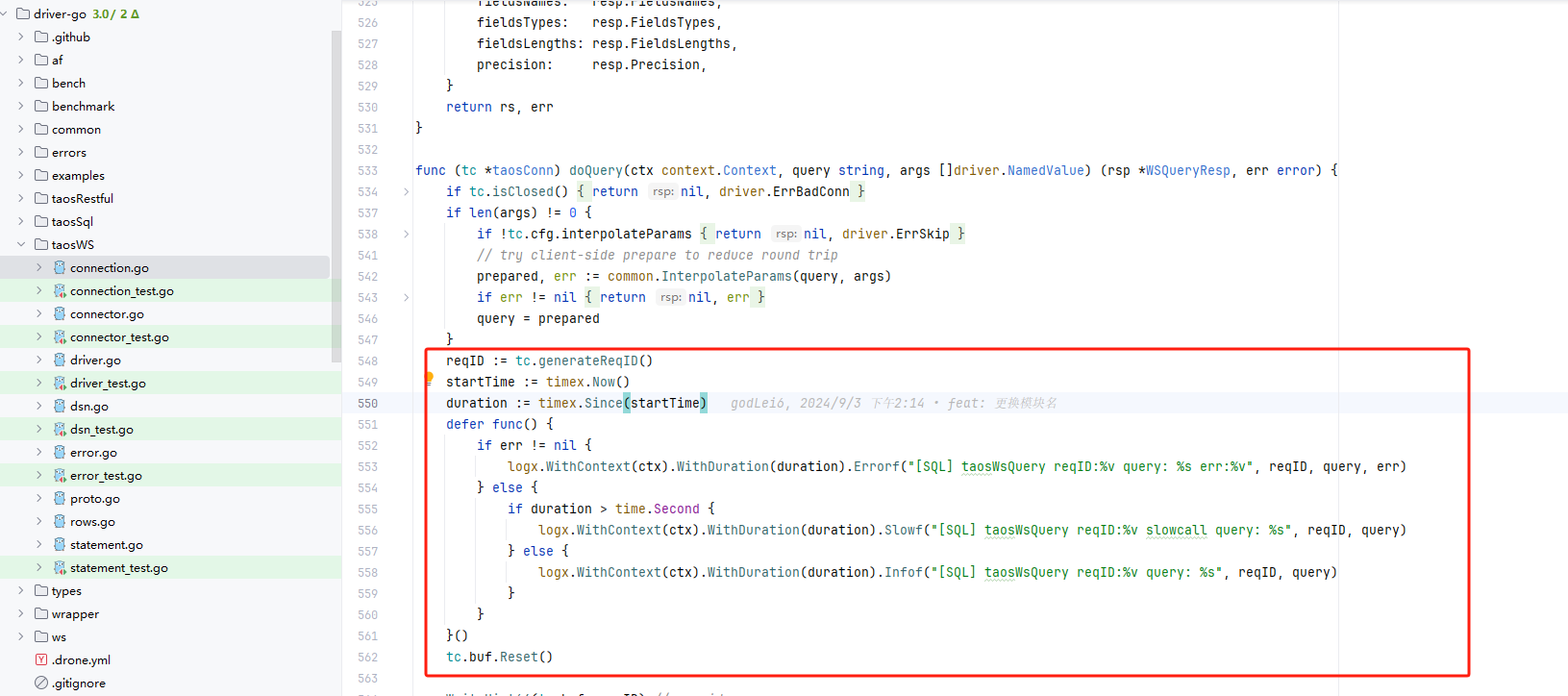
最后,我们还需要解决链路追踪的问题:我们需要知道一个sql的执行耗时,及能够和业务的链路id打通,能够通过日志查到sql是谁执行的,怎么执行的.
官方的驱动比较底层,但是好在打通了context,而 联犀使用的链路追踪也是通过context来进行传递的,那我们只需要在执行sql的地方打上日志即可.
官方的驱动地址是: github.com/taosdata/driver-go, 我们改造的地址是: github.com/i-Things/driver-go
无论是那种连接方式(http,ws,cgo),日志都是打在driver-go/taosWS/connection.go connection.go文件中。
联犀打印的日志如下:
# 总结
通过以上一系列的工作,我们成功地将 TDengine 的建模、写入、查询、运维整个流程的打通并且与物联网业务完美地融合起来。
因此为了感谢 TDengine 的对我们产品的帮助,特作此文,希望可以给各位各位相关从业人士一些帮助。
# 附录
联犀开源地址: https://gitee.com/unitedrhino (opens new window)
td orm定制: https://gitee.com/unitedrhino/squirrel (opens new window)
td官方驱动定制: https://gitee.com/unitedrhino/driver-go (opens new window)

